This notice actually appeared on the front door of my house for a while.
As with the notice above, notice & consent online is worse than a fail. It’s absurd. But it helps to have sources that explain how ceremonies promising privacy online will always fail when those running the ceremonies are also incentivised to violate their privacy commitments (or not to make them in the first place). I’m including coverage of adjacent and dependent topics (e.g. adtech and CRM/CX). Of course, this is all toward setting the stage for MyTerms. Feel free to add your own.
What is your best friend’s personal brand? How about your spouse’s?
Those questions came to mind as I read through The Death of Merchandising in an Online World, by Dana Blankenhorn, who is reliably wise. In that post, Dana correctly observes that brand value is declining as merchandising shifts from stores to online services, and to influencers who are also stores.
I think there’s also something else going on at the same time: the shift in media from real advertising to the online equivalent of junk mail, which is what you see with nearly every ad you encounter on your browsers and apps. To marketers, browsers and apps are boxes for junk mail, which at its most ideal is personalized by surveillance. As I put it in Separating Advertising’s Wheat and Chaff, ” Madison Avenue fell asleep, direct response marketing ate its brain, and it woke up as an alien replica of itself.”
I wrote that a decade ago. With AI today, that alien replica is the real thing. Madison Avenue is now AM radio, with a whip antenna and tail fins.
Brand advertising worked best when “the media” were mostly print and broadcast. Sources of both were so few that they all fit on a newsstand and the dials of radios and TVs. To operate a source of either, you needed a printing plant or transmitting towers. Publishers and broadcasters are still around, but now their goods are mostly distributed over the Internet and consumed through glowing rectangles. And they’re competing in a world where the abundance of other sources of content is incalculably vast. In that world, the only places you can still reliably create and maintain brands is by sponsoring live events. Especially sports. That’s why I know fifteen minutes will save me fifteen percent with Geico, even though Geico stopped saying that years ago. I also know that you only pay for what you need with Liberty Mutual. And I’ll never get the Shaefer Beer jingle out of my mind.
On the whole, however, branding has finished running the same course as the broadcasting it paid for.
It helps to remember that the words brand and branding were borrowed from ranching. They applied especially well when people had few choices of media, and few if any ways to avoid ads meant to burn the names of companies and products onto mental hides.
What we really (or at least should) mean by brand today is reputation. How a business obtains that in our still-new Digital Age (now with AI!) is an open question.
I believe the answer will come from the natural world, where markets have been working far longer than we’ve had digital media, broadcasting, or print. It was in the natural world that two very different people—one an athiest and the other a pastor—separately explained to me, not long after The Cluetrain Manifesto came out, that markets are not just about transactions and (as Cluetrain insisted) conversations. They are about relationships.
Marketing prevents those. Or shortcuts them. Especially as it continues to devolve into funnels at the bottom end of which are transactions alone, or entrapment in a company’s “loyalty” system.
The Internet and the Web were both designed to support maximum agency and independence for every entity using them. We can have far better markets and marketing if demand and supply both work with maximized agency, and scale in ways that are good for both. That’s the idea behind market intelligence that flows both ways.
Making and maintaining those kinds of relationships will be VRM+CRM, What those together will make are wholes that exceed the sum of either part.
MyTerms will give strength to the Internet’s fabric of human connections, through agentic agreements between people and the organizations that serve them.
The Internet is peer-to-peer, by design. It supports agreements between equals, for the good of both. On that equality a massive amount of new and better dealings can be built, on stronger foundations of mutual agency and respect.
MyTerms are contracts, which are binding mutual agreements between parties. They replace consents, which are corporate protections to which individuals can only acquiesce. Consents give individuals no record of having agreed to anything and cannot be audited or enforced. They are also annoying for both individuals and companies, with massive amounts of operational and cognitive overhead. In most cases they also don’t obey the settings people make.
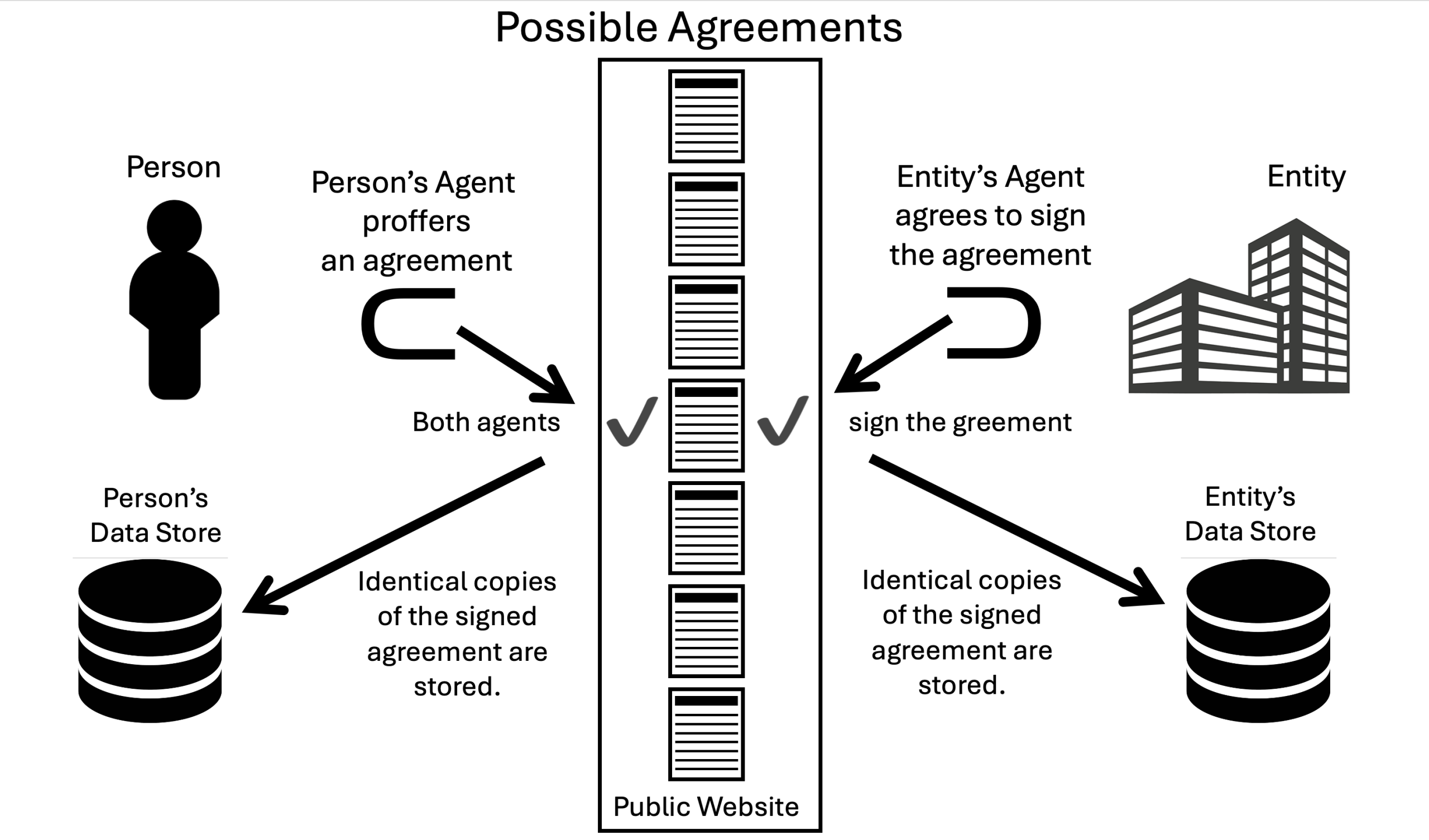
With MyTerms, individuals, operating as first parties, proffer a contract they choose from a limited list posted on a public website by a neutral nonprofit organization. The company, as the second party, can choose to agree to that contract or an alternate specified by the individual from the same list. Both sign the agreement electronically and keep matching records that can be audited later if need be. If the company declines to agree, the individual can keep a record of that choice, which they are free to share.
This process is described in a new standard from the IEEE called P7012, which is due for publication in January 2026. Its nickname is MyTerms, much as the nickname of IEEE 802.11 is Wi-Fi.
The most basic MyTerms agreement is for services only. This resets the marketplace to what we have in the natural world, where one can visit an establishment for the services it provides, in faith that one will not be tracked out of it for any reason, and data about oneself will not be sold or given to others. It also commits the individual to respect for the establishment and the services it provides.
With MyTerms, voluntary and genuine relationships can be built on a foundation of mutual respect and willingness to engage. Following a MyTerms agreement, individuals can selectively disclose information about themselves and their intentions, and additional services might be provided, in mutually agreeable and fruitful ways.
In this manner, companies can come to know individuals far better than has ever been possible through unwelcome surveillance and algorithmic guesswork and manipulation. Genuine relationships can also replace the coercive kind typified by “loyalty” programs meant constantly to manipulate customers. (Consider how marketers, without irony, speak of customers as “targets” to be “acquired,” shoved through a “funnel,” “controlled,” “managed,” and “locked in” as if they were slaves or cattle.)
The MyTerms standard also says that both sides will use machine agents to make agreements. These can be as simple as browser plug-ins on the individual side and server plug-ins on the corporate side. They can also be AI agents, which is why it is opportune for the standard to be published in an age when AI is still a new and rapidly evolving—for both companies and individuals.
For maximized agency on both sides, AI agents must be private instruments of full sovereignty, meaning they work privately and exclusively for each party. They cannot be instruments of surveillance or control by outside actors of any kind. Working exclusively will also maximize agency for both sides.
Civilization requires privacy. Simple as that. We worked out privacy in the natural world with technologies such as clothing and shelter, and well-understood ways to signal our intentions. The digital world, however, is still new, and not civilized. We lack the equivalents of clothing and shelter, and in their absence, surveillance has become the norm. So has the theater of consent, with its insincere and ineffective cookie notices.
The only way to obtain personal privacy and make good on the Internet’s original promises is with mutually beneficial agreements that begin with the simple privacy requirements we as individuals present to the corporations of the world. With MyTerms, we can start civilizing the worldwide public marketplace, making it a safe and productive environment for business, and everything else that depends on it.
MyTerms (IEEE P7012) is on track to be ProjectVRM’s biggest achievement—and maybe the biggest thing on the Net since the Web. I’m biased, but I believe it.
Here is an alphabetized list of some protocols that I know so far, and what I think they might do (given my incomplete knowledge across all of them.). Note that the standard never says “user,” which has subordinate and dependent implications. It calls the first party a “person” or an “individual,” and the second party an “entity.”
A2A Protocol — “An open protocol enabling communication and interoperability between AI agents, giving them a common language – irrespective of the framework or vendor they are built on.” More here.
ActivityPub — Can publish or reference a MyTerms URI in actor metadata or message extensions so follows/interactions and happen under the person’s terms.
AT Protocol — Can include a MyTerms pointer in profile schemas or event metadata so interactions can be logged under the proffered terms.
Beckn Protocol — Can carry a MyTerms URI (or the terms JSON) in discovery/order messages and bind acceptance in the async ACK/NACK flow.
DIDComm v2 — Can attach MyTerms as a claim/document in DID-to-DID messages; the counterparty signs/acks to bind the contract.
GNAP — Can pass a MyTerms URI/hash in the grant/interaction; record acceptance alongside the grant.
HCP (Human/Hyper-Capability Protocol) — Called (at that link) “a user-owned, secure, and interoperable preference layer that grants individuals granular, revocable control over how their data steers AI systems,” it can store a MyTerms reference in the person’s preference set, gate releases on acceptance, and optionally include the URI/hash in OAuth flows to enable audit.
HTTP Message Signatures (RFC 9421) — Can bind MyTerms to specific HTTP exchanges by signing requests/responses that include a terms reference.
HTTPS — This is generic transport. It can attach or link MyTerms in headers/body and have the counterparty echo/ack to the transaction log.
JLINC — Designed for MyTerms-like ceremonies, it can carry a MyTerms ID/hash for “data shared under an agreement.”
Matrix — Can include a MyTerms pointer in a profile state or an event content so rooms/interactions are conducted under the person’s terms.
Model Context Protocol (MCP) — Can send a MyTerms URI/hash in a tool/agent handshake or call metadata, so tools operate under those terms and log acceptance.
NANDA (Internet of AI Agents) — Can expose MyTerms during agent discovery/handshake and metadata in registry so agents negotiate under the person’s terms.
Nostr — Can include a MyTerms reference in profile/event tags so relays and clients can honor and log acceptance.
OAuth 2.0 — Can carry MyTerms as a parameter or in a request object, recording consent/acceptance with the access transaction.
OpenID Connect — Can include a MyTerms URI/hash as a claim (e.g., in the ID token) or request object with RP/OP log acceptance.
Solid — Can host the person’s MyTerms in their wallet (formerly called a pod) and require apps or services to transact under those terms for resource access.
UMA 2.0 — Can treat MyTerms as a policy at the resource server and share only with parties that have accepted the person’s terms.
Web Linking (RFC 8288) — Can advertise a MyTerms URI via Link: headers or a /.well-known/ location for discovery and binding.
Please give me additions, corrections, and improvements. And forgive the need for all of those changes. I think it’s important at this stage to get a list of possible protocols out there, and to get the discussion rolling. Thanks!
This appears atop a DuckDuckGo search. A few years ago, numbers 1 and 2 would have been down next to number 6.
I wrote a chapter on Agency in The Intention Economy because back then (2012) the word mostly meant an insurance or advertising business. The earlier meaning, derived from the Latin agere, meaning “to do,” had mostly been forgotten.
Now agency is everywhere, and is given fresh meaning with the adjective agentic.
We can thank AI for that. The big craze now is to have AI agents for everything, and to make all kinds of stuff “agentic,” using AI.
Including each of us. We should all maximize our agency with our own personal AI.
With that in mind, and thinking toward upcoming conferences on AI (and our own VRM Day, this coming October 19th ), I just added this section to the VRM Development Work page in our wiki:
Personal AI
Balnce.ai † “Your personal AI, your loyal agents and a network that makes your data work for you.”
Base.org “Base is built to empower builders, creators, and people everywhere to build apps, grow businesses, create what they love, and earn onchain.”
Decentralized AI Agent Alliance “…offers a compelling alternative, giving individuals sovereignty, including ownership of their identity and data.”
Kwaai “a volunteer-based AI research and development lab focused on democratizing artificial intelligence by building open source Personal AI.” Also, KwaaiNet “AI running distributed on a P2P fabric,” now (July 2025) with Verida “Create and deploy personalized AI agents with secure data connectors, custom knowledge bases, and configurable inference endpoints.”
The AI Alliance “building and advancing open source AI agents, data, models, evaluation, safety, applications and advocacy to ensure everyone can benefit.”
Please add more, or make corrections on what’s there. If you don’t have editing privileges, just write to me and I’ll make the changes. Thanks!
So here is a challenge for Admiral , OneTrust, and the rest of them: make VRM mean Vendor Relationship Management (like it says in Wikipedia).
Our case: real relationships are based on mutual trust, which can only happen if personal privacy is fully respected as a starting point. Consent management by cookie notice can’t cut it. For real trust, we need people to bring their own terms to every website’s table, and have agreements to those. This is why we, the ProjectVRM community, through Customer Commons (our nonprofit spinoff) and the IEEE P7012 (aka MyTerms) working group, created the draft standard (on track to become official early next year) for machine-readable personal privacy terms. Three years ago, I called MyTerms The Most Important Standard in Development Today. The CMP business can help make it so, by getting on the Cluetrain.
Here are some opportunities:
CMPs can provide sites & services with easy ways to respond to MyTerms choices brought to the table by visitors. Let’s call this a Terms Matching Engine.The current roster of terms we’re working with at Customer Commons (abbreviated CuCo, hence the cuco.org shortcut) starts with CC-BASE, which is “service provision only.” It says to a website, “just give me your service, and nothing more.” In other words, no tracking. Yet. Negotiation toward additional provisions comes after that. Those can be anything, but they should be in the spirit of We’re starting with personal privacy here, and the visitor sets the terms for that.
There is a whole new business (which, like the VPN, grammar-help, and password management businesses, people would pay for) in helping people present, manage, remember, and monitor compliance with their terms, and what additional agreements have been arrived at. This can involve browser add-ons such as the one pictured on the ProjectVRM r-button page. CMP companies can make money there too, adding a C2B business to their B2B ones.
Go beyond #2 to provide real VRM. Back in the last millennium, Iain Henderson pointed out that B2B relationships tend to have hundreds or thousands of variables over which both parties need to agree. Nitin Badjatia, another CRM veteran (and a Customer Commons board member like Iain and myself), has also pointed out that companies like Oracle have long provided AI-assisted ways for B2B relationships to arrive at contractual agreements. The same can work for C2B, once the base privacy agreement is established. There can be a business here that expands on what gets started with that first agreement.
Verticals. There can be strong value-adds for regulated industries or companies wanting to acquire and signal accountability, or look for firmer ways to establish a privacy regime better than the called consent, which doesn’t work (except as thin ass-covering for companies fearing the GDPR and the CCPA). For example: banks, insurers, publishers, health care providers.
For people (not just corporate clients), CMPs could offer browser plugins or apps (mobile and/or computer) that help people choose and present their privacy terms, track who honors them, notify them of violations, and have r-buttons mean something. Or multiple things.
Here is what a VRM-friendly person in the UK came up with as a prototypical first by a CMP away from cookie notices:
That was after this post went up. (Which is great.)
Obviously, we want cookie notices (and other forms of friction) to go away, but we also want CMPs to have a nice way to participate in a customer-led world in which intention-based economies can grow.
And here is an example of r-buttons in a browser:
Real relationships, including records of agreements, can be unpacked when a person (not a mere “user”) clicks on either the ⊂ or the ⊃ symbols. There are golden opportunities here for both VRM and CRM vendors. And, of course, companies such as Admiral and OneTrust working both sides—and being truly trusted.
Customers need privacy, respect, and the ability to provide good and helpful information to the companies they deal with. The good clues customers bring can include far more than what companies get today from their CRM systems and from surveillance of customer activities. For example, market intelligence that flows both ways can happen on a massive scale.
But only if customers set the terms.
Now they can, using a new standard from the IEEE called P7012, aka MyTerms. It governs machine readability of personal privacy terms. These are terms that customers proffer as first parties, and companies agree to as second parties. Lots of business can be built on top of those terms, which at the ground level start with service provision without surveillance or unwanted data sharing by the company with other parties. New agreements can be made on top of that, but MyTerms are where genuine and trusting (rather than today’s coerced and one-sided) relationships can be built.
When companies are open to MyTerms agreements, they don’t need cookie notices. Nor do they need 10,000-word terms and conditions or privacy policies because they’ll have contractual agreements with customers that work for both sides.
On top of that foundation, real relationships can be built by VRM systems on the customers’ side and CRM systems on the corporate side. Both can also use AI agents: personal AI for customers and corporate AI for companies. Massive businesses can grow to supply tools and services on both sides of those new relationships. These are businesses that can only grow atop agreements that customers bring to the table, and at scale across all the companies they engage.
This is the kind of thing that four guys (me included)† had in mind when they posted The Cluetrain Manifesto* on the Web in April 1999. A book version of the manifesto came out in early 2000 and became a business bestseller that still sells in nine languages. Above the manifesto’s 95 theses is this master clue**, written by Christopher Locke:
MyTerms is the only way we (who are not seats or eyeballs or end users or consumers) finally have reach that exceeds corporate grasp, so companies can finally deal with the kind of personal agency that the Internet promised in the first place.
The MyTerms standard requires that a roster of possible agreements be posted at a disinterested nonprofit. The individual chooses one, the company agrees to it (or not). Both sides keep an identical record of the agreement.
The first roster will be at Customer Commons, which is ProjectVRM’s 501(c)3 nonprofit spinoff. It was created to do for personal privacy terms what Creative Commons does for personal copyright licenses. (It was Customer Commons, aka CuCo, that the IEEE approached with the idea of creating the MyTerms standard.)
Work on MyTerms started in 2017 and is in the final stages of IEEE approval process. While it is due to be published early next year, what it specifies is simple:
Individuals can choose a term posted at Customer Commons or the equivalent
Companies can agree to the individual’s choice or not
The decision can be recorded identically by both sides
Data about the decision can be recorded by both sides and kept for further reference, auditing, or dispute resolution
Both sides can know and display the state of agreement or absence of agreement (for example, the state of a relationship, should one come to exist)
MyTerms not a technical spec, so implementations are open to whatever. Development on any of those can start now. So can work in any of the six areas listed above.
The biggest thing MyTerms does for customers—and people just using free services—is getting rid of cookie notices, which are massively annoying and not worth the pixels they are printed on. If a company really does care about personal privacy, it’ll respect personal privacy requirements. This is how things work in the natural world, where tracking people like marked animals has been morally wrong for millennia. In the digital world, however, agreements need to be explicit, so programming and services can be based on them. MyTerms does that.
For business, MyTerms has lots of advantages:
Reduced or eliminated compliance risk
Competitive differentiation
Lower customer churn
Grounds for real rather than coerced relationships (CRM+VRM)
Grounds for better signaling (clues!) going in both directions
Reduced or eliminated guesswork about what customers want, how they use products and services, and how both might be improved
Lawyers get a new market for services on both the buy and sell sides of the marketplace. Companies in the CMP (consent management platform) business (e.g. Admiral and OneTrust) have something new and better to sell.
Lawmakers and Regulators can start looking at the Net and the Web as places where freedom of contract prevails, and contracts of adhesion (such as what you “agree” to with cookie notices) are obsolesced.
Developers can have a field day (or decade). Look for these categories to emerge
Agreement Management Platforms – Migrate from today’s much-hated consent management platforms (hello OneTrust, Admiral, and the rest).
Vendor Relationship Management (VRM) Tools and services – Fill the vacuum that’s been there since the Web got real in 1995.
Customer Relationship Management (CRM) – Make its middle name finally mean something.
Customer Data Return (CDR) – Give, sell back, or share with customers the data you’ve been gathering without their permission since forever. Talking here to car companies, TV makers, app makers, and every other technology product with spyware onboard for reporting personal activity to parties unknown.
Platform Relief – Free customers from the walled gardens of Apple, Microsoft, Amazon, and every other maker of hardware and software that currently bears the full burden of providing personal privacy to customers and users. Those companies can also embrace and help implement MyTerms for both sides of the marketplace.
New dances between customers and companies, demand and supply. (“The Dance” is a closing chapter of The Intention Economy.)
New commercial ecosystems can grow around a richer flow of clues in both directions, based on shared interest and trust between demand and supply.
Surveillance capitalism will be obsolesced — and replaced by an economy aligned with personal agency and respect from customers’ corporate partners.
A new distributed P2P fabric of personally secure and shared data processing and storage — See what KwaaiNet + Verida, for example, might do together.
All aboard!
†Speaking for myself in this post. I invite the other two surviving co-authors to weigh in if they like.
*At this writing, the Cluetrain website, along with many others at its host, is offline while being cured of an infection. To be clear, however, it will be back on the Web. Meanwhile, I’m linking to a snapshot of the site in the Internet Archive—a service for which the world should be massively grateful.
**The thesis that did the most to popularize Cluetrain was “Markets are conversations,” which was at the top of Cluetrain’s ninety-five theses. Imagining that this thesis was just for them, marketers everywhere saw marketing, rather than markets, as “conversations.” Besides misunderstanding what Cluetrain meant by conversation (that customers and companies should both have equal and reciprocal agency, and engage in human ways), marketing gave us “conversational” versions of itself that were mostly annoying. And now (thank you, marketing), every damn topic is now also a fucking “conversation”—the “climate conversation,” the “gender conversation,” the “conversation about data ownership.” I suspect that making “conversation” a synonym for “topic” was also a step toward making every piece of propaganda into a “narrative.” But I digress. Stop reading here and scroll back to read the case for MyTerms. And please, hope that it also doesn’t become woefully misunderstood.
Look up customer journey or customer experience (aka CX) and you’ll find nothing about what the customer drives, or rides. All results will be for systems meant for herding customers like cattle into a chute that the CX business (no kidding) calls a sales funnel:
Do any customers want to go down these drains?
But let’s stick with the journey metaphor, because there are good people in the marketing business who have thought deeply about how people buy and own things. Chief among those people is Estaban Kolsky, of Constellation Research. He visualizes the journey in a way that not only gives weight to the ownership experience, but separates it from the sales experience :
As for our actual experience, we spend 100 percent of our lives with things we own, and just a tiny percentage on buying them. So the real ratio should look more like this:
…consider the curb weight of “solutions” in the world of interactivity between company and customer today. In the BUY loop of the customer journey, we have:
3. All the rest of marketing, which has too many segments for me to bother looking up
So, in the OWN loop we have a $0 trillion greenfield.
To enter that greenfield, we need customers to be in charge of their side of these relationships— preferably through means for interaction that customers themselves control—on terms that are agreeable to both sides, rather than the one-sided terms we suffer every time we click AGREE on a cookie notice.
To help imagine how that will work, I volunteer a real-world example from my own life.
A few years back, I bought a pair of LAMOMens Mocs at a shopping mall kiosk in Massachusetts. Here’s one:
I like them a lot. They’re very comfortable and warm on winter mornings. In fact I still wear them, even though the soles have long since come apart and fallen off. Here is how they looked after a few years of use:
I’m showing this so you, and LAMO, can see what happens, and how we can both use my experience—and those of other customers—to change the world.
See, I like LAMO, and would love to help the company learn from my experience with one of their products. As of today, there are four choices for that:
Do nothing (that’s the default)
Send them an email
Go on some website and talk about it. (A perfect Leightoncartoon in the New Yorker shows a couple registering at a hotel while the person behind the counter says, “If there’s anything we can do to make your stay more pleasant, just rant about it on the Internet.”)
So here is a fifth choice: give these moccasins their own virtual cloud, where LAMO and I can share intelligence about whatever we like, starting (on my side) with reports on my own experience, requests for service, or whatever. Phil Windley calls these clouds picos, for persistent compute objects. Picos are breeds of what Bruce Sterling calls spime: persistent intelligence for things. Picos have their own operating system (e.g., Wrangler, which Phil most recently posted about here), and don’t need intelligence on board. Just scan a QR code, and you’ll get to the pico. Here’s the QR code on one of my LAMO moccasins:
Go ahead and scan the code with your phone. You’ll get to a page that says it’s my moccasin.
That’s just one view of a potential relationship between me and Lamo — one in which I can put a message that says “If found, call or text _______.” Another view is on my own dashboard of things in my OWN cycle, and direct connections to every one of those companies. That relationship can rest on friendly terms in which I’m the first party and the company is the second party. (For more on that, see here and here.)
So look at the relationship between me and Lamo as a conduit (the blue cylinder below) that lives in the pico for my mocassin. That conduit goes from my VRM (vendor relationship management) dashboard to Lamo’s CRM (customer relationship management) system. There is no limit to the goodness that can pass back and forth between us, including intelligence about how I use my moccasins.
Let’s look at what can happen at either or both ends of that conduit.
A pico for a product is a CRM dream come true: a standard way for every copy of every product to have its own unique identity and virtual cloud (in which any data can live), and standard way any customer can report usage and other intelligence about any product they own—without any smarts needing to live on the thing itself.
If I scan that QR code, I can see whatever notes I’ve taken. I can also see whatever LAMO has put in there, with my permission. Also in that cloud is whatever programming has been done on it. Here is one example of simple relationship logic at work:
IF this QR code is scanned, THEN send LAMO a note that Doc has a new entry in our common journal.
Likewise, LAMO can send me a note saying that there is new information in the same journal. Maybe that information is a note telling me that the company has changed sole manufacturers, and that the newest Mens Mocs will be far more durable. Or maybe they’ll send a discount on a new pair. The correct answer for what goes in the common journal (a term I just made up) is: whatever.
Now let’s say LAMO puts a different QR code, or other identifier, in every moccasin it sells. Or has a CRM system that is alert to notifications from customers who have turned their LAMO moccasins into picos, making all those moccasins smart. LAMO can then not only keep up with its customers through CRM-VRM conduits, but tie interactions through those conduits to the dashboards of their accounting systems (from Xero or other companies that provide enriched views of how the company is interacting with the world).
Follow the links in the last paragraph (all to Wikipedia), and you’ll find each of them has “multiple issues.” The reason for that is simple: the customer is not involved with any of them. All those entries make the sound of industries talking to themselves — or one hand slapping.
This is an old problem that can only be fixed on the customer’s side. Before the Internet, solving things from the customer’s side — by making the customer the point of integration for her own data, and the decider about what gets done with that data — was impossible. Now that we have the Internet, it’s very possible, but only if we get our heads out of business-as-usual and back into our own lives. This will be good for business as well.
A while back I had meetings with two call center companies, and reviewed this scenario:
A customer scans the QR code on her cable modem, activating its pico.
By the logic described above, a message to the call center says “This customer has scanned the QR code on her cable modem.”
The call center checks to see if there is an outage in the customer’s area, and — if there is — finds out how soon it will be fixed.
The call center sends a message back saying there’s an outage and that it will be fixed within X hours.
In both cases, the call center company sai,d “We want that!” Because they really do want to be fully useful. And — get this — they are programmable.
Unfortunately, in too many cases, they are programmed to avoid customers or to treat them as templates rather than as individual human beings who might actually be able to provide useful information. This is old-fashioned mass-marketing thinking at work, and it sucks for everybody. It’s especially bad at delivering (literal) on-the-ground market intelligence from customers to companies.
Call centers would rather be sources of real solutions rather than just customer avoidance machines for companies and anger sinks for unhappy customers. The solution I’m talking about here takes care of that. And much more.
Now let’s go back to shoes.
I’m not a hugely brand-loyal kind of guy. I use Canon cameras because I like the long-standing 5D user interface more than the competing Nikon ones, and Canon’s lens prices tend to be lower. I use Apple computers because they’re easy to get fixed and I can open a command line shell and get geeky when I need to. I drive a 2017 VW wagon because I got it at a good price. And I buy Rockport shoes because, on the whole, they’re pretty good.
Used to be they were great. That was in the ’70s and early ’80s when Saul and Bruce Katz, the founders, were still in charge. That legacy is still there, under Reebok ownership; but it’s clear that the company is much more of a mass marketing operation than it was back in the early days. Still, in my experience, they’re better than the competition. That’s why I buy their shoes. Rockports are the only shoes I’ve ever loved. And I’ve had many.
So here is a photo I took of wear-and-tear on two pairs of Rockport casual shoes I still use, because they’re damned comfortable:
Shots 1 and 2 are shoes I bought in June 2012, and are no longer sold, near as I can tell. (Wish they were.) Shots 3 and 4 are of shoes called Off The Coast 2 Eye. I bought mine in late 2013, but didn’t start wearing them a lot until early this year. I bought both at the Rockport store in Burlington Mall, near Boston. I like that store too.
The first pair has developed a hole in the heel and loose eyelet grommets for the laces around the side of the shoe. The hole isn’t a big deal, except that it lets in water. The loose eyelets are only a bother when I cross my feet sitting down: they bite into the other ankle. The separating outer sole of the second pair is a bigger concern, because these shoes are still essentially new, and look new except for that one flaw. A design issue is the leather laces, which need to be double-knotted to keep from coming undone, and even the double-knots come undone as well. That’s a quibble, but perhaps useful for Rockport to know.
I’d like to share these experiences privately with Rockport, and for that process to be easy. Same with my experiences with LAMO moccasins.
It could be private if Rockport and LAMO footwear came with QR codes for every pair’s pico — it’s own cloud. Or if Rockport’s CRM or call center system was programmed to hear pings from my picos.
Ideally, customers would get the pico along with the shoe. Then they would have their own shared journal and message space — the conduit shown above — as well as a programmable system for creating and improving the whole customer-company relationship. They could also get social about their dialogs in their own ways, rather than only within Facebook and Twitter, which are the least private and personal places imaginable.
This kind of intelligence exchange can only become a standard way for companies and customers to learn from each other if the code for picos is open source. If Rockport or LAMO try to “own the customer” by locking her into a closed company-controlled system — the current default for customer service — the Internet of Things will be what Phil calls “the Compuserve of things”. In other words, divided into the same kind of closed and incompatible systems we had before the Net came along.
One big thing that made the Internet succeed was substitutability of services. Cars, banks, and countless other product categories you can name are large and vital because open and well-understood standards and practices at their base have made substitutability possible. Phil says we can’t have a true Internet of Things without it, and I agree.
The smartest people working for companies are their customers. And the best way to activate customer smarts is by giving them scale. That’s what picos do.
As a bonus, they also give companies scale. If we can standardize picos, we’ll have common and standard ways for any customer and any company to relate to each other through any VRM + CRM system. Think about how much more, and better, intelligence a company can get from its customers this way, rather than through the ones barely succeeding now, where the company does all the work, and fails to know an infinitude of useful stuff customers could be telling them. Think about how much more products can be improved, an iterated over time. Think about how much more genuine loyalty can be created and sustained with this kind of two-way system.
Then think how much companies can save by not constantly spying on customers, guessing about what they might want, spamming them with unwanted and unnecessary sales messages, maintaining systems try to relate but actually can’t, and herding customers into imaginary funnels that customers would loathe if they could see what’s going on.
It’s a lot.
So let’s start working on growing a sane world of business that’s based on market intelligence that flows both ways, instead of the surveillance-based guesswork and delusional imaginings of marketing that smokes its own exhaust. We can do it, privately, and at scale.
Here’s one graphic from the piece, with its caption:
Illustration of the Rec4Agentverse. The left side depicts three roles in the RecAgentverse: the user, the Agent Recommender, and Item Agents, along with their interconnected relationships. In contrast to traditional recommender systems, the Rec4Agentverse has more intimate relationships among the three roles. For instance, there are multi-round interactions between 1) users and Item Agents and 2) the Agent Recommender and Item Agents. The right side demonstrates how the Agent Recommender can collaborate with Item Agents to affect the information flow of users and offer personalized information services.
With VRM, however, we need our own personal AI agents, and useful data that’s not limited to what’s gathered by surveillance (which we can assume is most if not all of the Information layer).
So I started a conversation with ChatGPT. I’ll divide it into sections:
Who wrote the CACM piece
The state of recommendation science
Who is working on personal AI
How one can get started
Forms of personal data to manage
There’s a lot here. The meat of it, for ProjectVRM purposes, starts in section 3. (The first two are more about what we’re up against.) Please read the whole thing and help us think through where to go with the challenge facing us. As we see in section 3, we do have some stuff on our side.
1. Who wrote the CACM piece
Me:
Can you tell me more about the authors here: https://cacm.acm.org/research/envisioning-recommendations-on-an-llm-based-agent-platform/?
ChatGPT:
🧑💼 Jizhi Zhang
Affiliation: University of Science and Technology of China (USTC), Data Science Lab (inferred from USTC page)cacm.acm.org+14data-science.ustc.edu.cn+14x.com+14. Research Interests: Recommendation systems, LLM-based agent platforms, and interactive intelligent systems—his lead authorship and continued work on Prospect Personalized Recommendation on LLM-Based Agent Platform (arXiv Feb 2024) reinforce thisarxiv.org.
Affiliations: While CACM doesn’t list this, Jizhi Zhang and Fuli Feng are part of USTC’s Data Science Lab; Tat‑Seng Chua is a distinguished researcher from the National University of Singapore known for multimedia and information retrieval. Expertise: A mix of recommender system design, LLM-agent evaluation, multimedia analysis, and human-AI interaction—reflecting a blend of USTC’s strengths and CACM relevancedata-science.ustc.edu.cn+8cacm.acm.org+8data-science.ustc.edu.cn+8linkedin.com+4arxiv.org+4researchgate.net+4.
🧑🎓 Wanhong Xu
Affiliation: USTC Data Science Lab (USTC LDS), contributor to the same article . Role: Emerging researcher whose latest publication is this Rec4Agentverse article, indicating an early-career focus in LLM-based recommender systemslinkedin.com+8data-science.ustc.edu.cn+8linkedin.com+8.
🧠 Broader Context & Contributions
The group operates at the intersection of Large Language Models, agent-oriented systems, and recommender systems, pioneering a Rec4Agentverse paradigm that treats LLM-powered agents as “recommendable” items collaborating with one another—an evolution of traditional recommendation frameworkscacm.acm.org+5cacm.acm.org+5cacm.acm.org+5. Their work continues earlier research (e.g., Prospect Personalized Recommendation… in Feb 2024), solidifying their ongoing commitment to expanding intelligent, conversational recommendation platformsarxiv.org.
🧭 Why This Matters
Academic Thought Leadership: Jizhi Zhang and colleagues are pushing forward thinking about how recommendations can evolve when agents—not passive items—are central. Institutional Backing: All deeply connected to USTC’s Data Science Lab, underscoring strong Chinese academic investment in AI-driven recommender innovation. Collaborative Reach: Including scholars like Tat‑Seng Chua broadens the research to include international perspectives in multimedia and retrieval systems.
In summary: This team is a multidisciplinary cohort—centered at USTC with international collaboration—who are pioneering the idea that LLM agents can become interactive, dynamic items in recommender systems. Their work positions them at the forefront of intelligent agent systems and could reshape how platforms personalize experiences in the future.
If you’re curious about any individual’s past publications, citation impact, or related work (e.g., on Agent4Rec), I’d be happy to dive deeper!
3. The state of recommendation science
Me:
How large is the emerging science, within the AI field, of recommendations?
ChatGPT:
The science of recommendations, particularly within the AI field, is not just emerging—it’s a massive, rapidly evolving subfield that is both academically rich and commercially dominant. That said, it’s also entering a new phase, driven by the rise of large language models (LLMs), interactive agents, and multimodal platforms.
📚 Academic Scope
1. Established Field: Recommender Systems
Recommender systems (RecSys) are a well-developed domain within AI and machine learning, with roots in the 1990s.
Annual conferences like: ACM RecSys (since 2007) SIGIR, KDD, WSDM, and NeurIPS regularly feature recommendation research.
Thousands of papers annually on topics like:
Collaborative filtering
Matrix/tensor factorization
Deep learning for recommendation
Fairness, transparency, and explainability in RecSys
Reinforcement learning and bandit algorithms for personalization
🔎 As of 2024, over 60,000 papers in academic databases (e.g., Google Scholar) are tagged or indexed under “recommender systems”.
📈 Current Trends & Expanding Frontiers
2. LLMs + Recommendation = New Subfield
A major shift is underway: integrating Large Language Models (LLMs) into recommendation systems.
These go beyond “you may also like” to:
Use natural language context and dialogue
Generate explanations, not just rankings
Support conversational recommendation Coordinate agent ecosystems, e.g., multi-agent reasoning environments
Example paradigms:
RecMind – reasoning-aware recommendation agents Rec4Agentverse – treating agents as recommendable entities ChatRecs – integrating LLMs into live user conversations
3. Multimodal & Multitask Integration
Systems increasingly blend text, image, video, behavior, and user feedback.
LLMs allow richer personalization using complex user intent derived from unstructured data.
4. Industry Investment
FAANG companies (especially YouTube, Netflix, Amazon, TikTok, and Spotify) base their core user experience on AI-driven recommendation.
Billions of dollars are spent optimizing:
Ranking quality
Engagement prediction
Real-time inference
Federated and privacy-preserving personalization
Not new, but rapidly evolving Core to AI applications, especially with LLMs and agents One of the most commercially and socially impactful domains in modern AI Growing into new subfields (e.g. Rec4Agentverse, LLM Rec, multi-agent Rec)
Let me know if you’d like a visual map of how the recommendation science ecosystem is structured—or who the top authors and institutions are in this space
3. Who is working on personal AI
Me:
And who, if anyone, is working to provide customers with their own personal AI tools: ones that work for them, to empower their own agency in the marketplace? By which I mean truly personal AI, and not the kind personalized by some external LLM (or similar) system.
ChatGPT:
That’s an essential and forward-looking question—especially as most “AI for you” today really means “AI about you, for someone else.”
While Big Tech firms dominate personalized AI, a growing ecosystem is focused on truly personal AI—that is, AI you own, that works for you (not advertisers or platforms), and that enhances your agency in the marketplace and your life.
Here are the most notable people, projects, and initiatives advancing truly personal AI today:
🧠 1. Kwaai and pAI-OS (South Africa / Global)
Kwaai is building an open-source, user-sovereign personal AI OS called pAI-OS.
Designed to run locally or at user discretion, with full data ownership, modular agent systems, and plugin capability.
Aligns with IEEE P7012 (“MyTerms”) privacy standards (see below).
Actively exploring intentcasting, customer signaling, and VRM (Vendor Relationship Management).
Site: https://kwaai.ai
🛠️ 2. Indie AI and Personal Agent projects
Several smaller open-source initiatives are trying to build personal agent toolkits that you can host and configure:
Examples:
AutoGen Studio (Microsoft) – allows building agent workflows, some of which can be user-defined. But it’s not yet fully personal or private. Langroid – open-source framework for local agent-based LLM systems. Designed for extensibility, can be made personal with effort. OpenDevin, Superagent, Auto-GPT – can be self-hosted, though most are still tool-centric rather than user-centric. Personal.ai – A commercial startup that says it is personal, but uses centralized storage and fine-tuning, so actual user control is limited.
🔍 Reality check: Most of these still rely on external LLMs (like OpenAI or Anthropic), even if they claim to be “your AI”.
🌐 3. Solid Project (by Tim Berners-Lee)
While not AI per se, Solid is a decentralized identity and data storage architecture that allows individuals to store their own data in personal data pods.
AI tools can be layered on top to access only the data you choose to share.
Foundation for personal AI assistants that can work with your data, not on others’ clouds. https://solidproject.org
📜 4. IEEE P7012 – MyTerms
A standard being developed to flip the notice-and-consent regime—so individuals, not companies, dictate the terms of data use.
Backed by Customer Commons and designed to support intentcasting and personal marketplace signaling.
This enables a personal AI to serve as your agent, enforcing your terms and engaging the marketplace on your behalf.
🧩 5. Project VRM (Vendor Relationship Management)
Initiated by Doc Searls to empower customers with tools to manage vendors, not just the reverse.
Envisions personal tools (including AI) to:
Signal intent
Manage service contracts
Retain records of offers, purchases, warranties
Avoid manipulation, surveillance, and lock-in
Project VRM is not a software project per se, but a framework guiding developers to build personal tools that support individual autonomy.
🔒 6. Open-source LLM stacks for local use
Several local LLM projects can be combined with personal data layers to build truly personal AI:
LM Studio – runs local models on desktop PrivateGPT – local inference + local documents Ollama – macOS-native interface for fast-running models like LLaMA, Mistral LangChain / LlamaIndex – frameworks for building RAG systems with local documents
These aren’t personal AI systems yet—but they are key ingredients.
🧭 Summary
Name / Project
What They Do
Status
Kwaai / pAI-OS
Open, personal AI OS and agent platform
Early but active
Solid
Personal data control layer
Stable; in use
IEEE P7012
Standards for user-enforced data terms
In development
Project VRM
Framework for tools that empower buyers
Thought leadership; toolkits emerging
Local AI frameworks
Tech foundations for personal AI
Available, DIY-friendly
🚧 The Gap
Despite this promising landscape, no major platform today delivers a fully integrated, easy-to-use personal AI that you own, configure, and direct—yet. But:
A personal AI revolution is underway, led by privacy advocates, open-source communities, and a few visionary developers—not Big Tech.
Would you like help putting together a DIY stack for your own personal AI toolkit based on this landscape?
Me:
Can you name some of the people in the personal AI revolution, and tell me what that DIY stack would contain?
ChatGPT:
Absolutely. Here’s a breakdown of key people involved in the personal AI movement, followed by a practical DIY stack you can start building today.
👤 People Leading or Advancing the Personal AI Revolution
These individuals aren’t all working on the same projects, but they’re aligned in trying to build AI that’s owned, run, and controlled by the individual—not centralized platforms.
🧑🔬 Tim Berners-Lee
Project: Solid (stewarded by ODI, commercially implemented by companies including TBLs Inrupt) Focus: Decentralized web and personal data ownership via data pods Impact: Infrastructure for privacy-respecting personal AI agents https://solidproject.org
👤 Doc Searls
Project: Project VRM, Customer Commons, IEEE P7012 Focus: Customer empowerment, intentcasting, reversing surveillance capitalism Impact: Philosophy and standards for customer-directed personal AI https://projectvrm.org
🧠 Tawanda Kembo & Kwaai team
Project: pAI-OS (personal AI operating system) Focus: Agent-centric open-source operating system for personal AI Impact: One of the few efforts aiming to create a complete personal AI stack https://kwaai.ai
🧑💻 Simon Willison
Project: Datasette, open tools for data management Focus: Personal data control, lightweight databases, LLM + local tooling Impact: Key figure in the open data + local AI tooling space https://simonwillison.net
🤖 Brian Roemmele
Project: Multiplex (personal voice AI) Focus: Voice-first personal assistants you run locally Impact: Vocal advocate for true personal AI, often referencing “software you own”
🛠️ A DIY Personal AI Stack (2025 Edition)
This stack assumes local-first, modular, privacy-respecting tools. You can mix and match based on your needs.
🧩 Core Components
Layer
Tools / Projects
Notes
1. OS Layer
Linux, pAI-OS (in dev)
Linux gives flexibility; pAI-OS aims to be a full personal AI OS
2. Local LLM Inference
Ollama, LM Studio, PrivateGPT, LocalAI
Run models like LLaMA 3, Mistral, Phi-3 entirely offline
3. Vector Database
Chroma, Weaviate, Milvus, or SQLite with FTS5
Store and retrieve embedded text data
4. Personal Indexing
LlamaIndex, LangChain, AutoGen, GPTPilot
Feed personal documents and data to your LLM
5. Personal Data Storage
Solid POD, Datasette, Obsidian
Your life’s data, structured and queryable
6. Personal Agent Framework
Superagent, CrewAI, Langroid, AutoGen
Design agents that act on your behalf, modular and scriptable
7. Front-end Interface
Gradio, Streamlit, Tauri app, Electron
Local GUI/UX to interact with your agent
8. Voice Interface (optional)
OpenVoice, Vosk, Whisper.cpp, Coqui TTS
Build voice-in/voice-out agent on your machine
🧠 Optional Add-ons
Offline search: Chat over your files, PDFs, photos, and emails with LlamaIndex + PrivateGPT Calendar/notes: Sync with Obsidian or local markdown-based knowledge base Browser agent: Auto-control browser via Puppeteer/Playwright for marketplace navigation
🧭 What’s Still Missing?
True personal OS integration (like what pAI-OS is trying to do)
Seamless data portability and contract enforcement (IEEE P7012 is working on it)
Trusted personal AI app ecosystem (some apps, like Beeper or Obsidian, are getting close)
Would you like a tailored recommendation for building a personal AI stack based on your technical skill level or use cases (e.g., journaling, research, negotiation, shopping, data querying)?
4. How can I get started?
Me:
Yes. My technical skill level is modest at best. I can write HTML and do very basic stuff in the command line. I have an extra laptop I can devote to solo work, and Ethernet to a 2.1GB/s symmetrical fiber connection to the Internet with no data limits.
ChatGPT:
Great — with your setup (modest technical skills, spare laptop, blazing-fast fiber), you’re in an excellent position to begin building a practical personal AI system without diving too deep into complex dev work. Here’s a recommended stack tailored to your current skills and goals:
🧰 YOUR PERSONAL AI STARTER STACK (2025)
🔧 1. Platform Base
Use a Linux distribution designed for ease of use and AI tinkering:
Recommended: Pop!_OS or Ubuntu 24.04 Easy GUI, good hardware compatibility, lots of online support
Optional: Use your laptop in “air-gapped” mode for privacy and full local control
🤖 2. Run a Local LLM with LM Studio
LM Studio (macOS/Windows/Linux) lets you run LLaMA 3, Mistral, Phi-3, and others without coding.
Built-in UI — chat with models locally, no internet required after download.
You can download 7B or 13B models based on your hardware.
Best for: private journaling, summarizing files, answering questions.
✅ Why it’s ideal for you:
GUI-based
Just click and download models
No API keys or command-line needed once installed
📁 3. Chat with Your Files (PrivateGPT / LlamaIndex)
PrivateGPT or GPTPilot can let you ask questions across PDFs, emails, and notes stored on your machine.
Start simple: drop files into a folder, let the AI index them. Optionally install via Docker (one command), or use their prebuilt apps.
✅ Use case:
“Summarize this research PDF”
“What did I write about project X last month?”
“Find the email where someone mentioned a refund”
📚 4. Knowledge Base + Journaling with Obsidian
Obsidian = Markdown-based knowledge base.
Everything you write stays local.
You can point LM Studio to your notes to query your own memory.
✅ Easy way to:
Keep private journals
Index your life
Ask your AI things like “What are my goals for June?”
🗂️ 5. Personal Data Management with Datasette
Datasette by Simon Willison lets you browse and query your own data with simple SQL and CSV files.
Feeds AI with structured personal info (purchases, inventory, plans, etc.)
You can install it with a single terminal command:
bash pip install datasette datasette serve your-data.db datasette serve your-data.db
✅ Combine with LM Studio to get responses like:
“What subscriptions do I need to cancel?”
“When did I last back up my photos?”
Use AutoBrowser or a simpler Puppeteer script to automate browsing tasks (like checking prices, news, account activity).
Start with prebuilt scripts. No coding needed if you copy/paste working examples.
🔒 7. Privacy Boosters
Run Tailscale or WireGuard to access your AI remotely if needed.
Use LocalAI or Ollama if you later want to run everything without GUI (more advanced).
🧭 Putting It All Together
Task
Tool
Chat privately with an AI
LM Studio
Summarize your own notes or PDFs
PrivateGPT or GPTPilot
Store and reflect on your life data
Obsidian, Datasette
Manage subscriptions and tasks
Datasette + Chat
Ask about your files or history
LlamaIndex or GPT over Obsidian notes
Use voice later (optional)
Whisper.cpp, OpenVoice (easy tools)
🪜 Next Steps (in plain order)
Install Pop!_OS or Ubuntu on your spare laptop
Install LM Studio and download a 7B model like Mistral or LLaMA 3 Start using it to answer personal questions and summarize documents
Add Obsidian to start journaling and reflecting
Try PrivateGPT or Datasette to search your past or track your life
Would you like a checklist or an install script to get started with this stack? I can also help you set up a file structure to begin tracking and querying your own data.
5. Forms of personal data to manage
Me:
The personal data I need to manage are health records (from 20-plus providers), financial records (fewer than health), travel records (including the kind kept by apps that watch my movements), subscriptions and other recurring payments, shows I have watched and on what channels or services (data gathered by my Samsung and Roku TVs and presumably shared with others but to which I don’t yet have access), continuing work and work history with various clients and employers, contacts, archival and current calendars, real estate, personal items bought or acquired from various sources and where they are kept or stored, and business dealings. What would be the file structure for all that, and how would I manage it? Note that I am not talking about shopping yet; that’s a separate concern.
ChatGPT:
Thanks for the detailed breakdown — you’re describing the foundation of a true personal data architecture: structured, queryable, and under your control. Let’s build you a file structure and management strategy that matches your needs without overcomplicating the tech.
📁 Recommended Top-Level Folder Structure
This folder structure is designed to be future-proof, machine-readable, and human-usable. Use plain folders, CSV/JSON/Markdown files, and optional SQLite databases to store structured data. You can later layer tools (like LLMs or Datasette) on top.
Use Obsidian for ongoing notes (e.g. travel journal, work logs)
Use Paperless-ngx (optional) to OCR and tag your scanned PDFs (health, finance)
Use GPS History Export from Google and Apple for travel/locations
Use email filters or Zapier to auto-download bills, statements, confirmations
4. Querying and Reviewing
Add one or more of these later:
Datasette → browse and search CSVs/SQLite locally
LM Studio + PrivateGPT → ask, “When did I last visit Dr. Chen?” or “What devices are in storage?”
LlamaIndex → index your file tree and let AI search/summarize it
✅ Summary of Benefits
Goal
This Setup Delivers
Total local control
You decide access, storage, retention
Future AI-readiness
Structured enough for agents to use
Easy to back up
Plain files, portable databases
Modular growth
Start simple, layer in AI when ready
Would you like me to generate a starter template with folder structure and some CSV/Markdown file formats filled in with mock data for each domain? That way you can load it directly into your system and start customizing.
Me again:
That’s it for now.
What should my next request be, or what other direction would you like me (or us) to take this?
Or, what are the learnings we have so far in this field that barely exists?
Oh, and excuse whatever inaccuracies ChatGPT may have floated above. Or give me fixes.
Thanks.
*The links are mine and based on searches for those names. I might have some of them wrong, however, since searches for those names bring up many scholars with the same names. And, while each name had a link, they all went to an author archive page that was absent (with one exception) of other contributions to the publication.