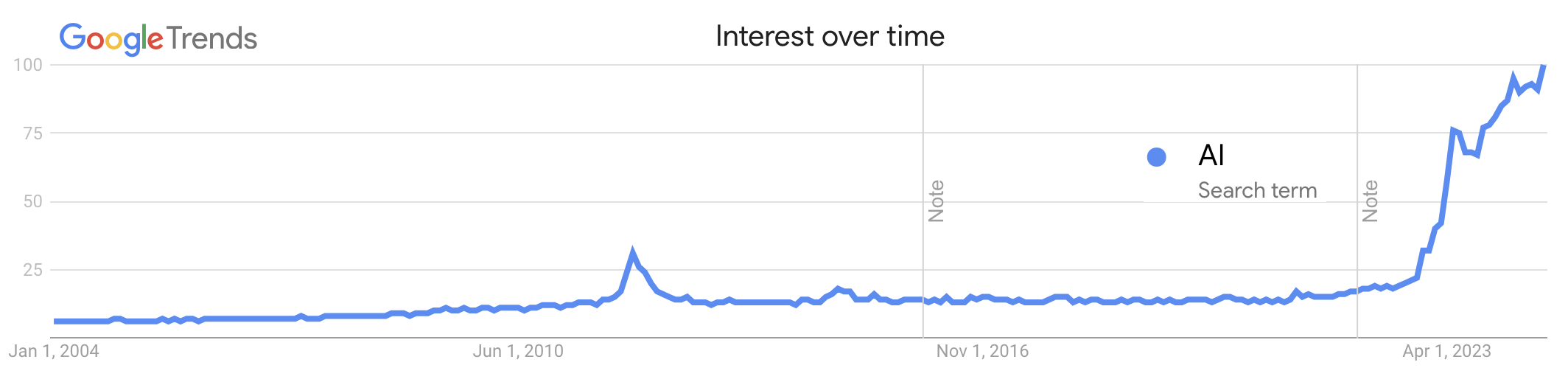
What is your best friend’s personal brand? How about your spouse’s?
Those questions came to mind as I read through The Death of Merchandising in an Online World, by Dana Blankenhorn, who is reliably wise. In that post, Dana correctly observes that brand value is declining as merchandising shifts from stores to online services, and to influencers who are also stores.
I think there’s also something else going on at the same time: the shift in media from real advertising to the online equivalent of junk mail, which is what you see with nearly every ad you encounter on your browsers and apps. To marketers, browsers and apps are boxes for junk mail, which at its most ideal is personalized by surveillance. As I put it in Separating Advertising’s Wheat and Chaff, ” Madison Avenue fell asleep, direct response marketing ate its brain, and it woke up as an alien replica of itself.”
I wrote that a decade ago. With AI today, that alien replica is the real thing. Madison Avenue is now AM radio, with a whip antenna and tail fins.
Brand advertising worked best when “the media” were mostly print and broadcast. Sources of both were so few that they all fit on a newsstand and the dials of radios and TVs. To operate a source of either, you needed a printing plant or transmitting towers. Publishers and broadcasters are still around, but now their goods are mostly distributed over the Internet and consumed through glowing rectangles. And they’re competing in a world where the abundance of other sources of content is incalculably vast. In that world, the only places you can still reliably create and maintain brands is by sponsoring live events. Especially sports. That’s why I know fifteen minutes will save me fifteen percent with Geico, even though Geico stopped saying that years ago. I also know that you only pay for what you need with Liberty Mutual. And I’ll never get the Shaefer Beer jingle out of my mind.
On the whole, however, branding has finished running the same course as the broadcasting it paid for.
It helps to remember that the words brand and branding were borrowed from ranching. They applied especially well when people had few choices of media, and few if any ways to avoid ads meant to burn the names of companies and products onto mental hides.
What we really (or at least should) mean by brand today is reputation. How a business obtains that in our still-new Digital Age (now with AI!) is an open question.
I believe the answer will come from the natural world, where markets have been working far longer than we’ve had digital media, broadcasting, or print. It was in the natural world that two very different people—one an athiest and the other a pastor—separately explained to me, not long after The Cluetrain Manifesto came out, that markets are not just about transactions and (as Cluetrain insisted) conversations. They are about relationships.
Marketing prevents those. Or shortcuts them. Especially as it continues to devolve into funnels at the bottom end of which are transactions alone, or entrapment in a company’s “loyalty” system.
The Internet and the Web were both designed to support maximum agency and independence for every entity using them. We can have far better markets and marketing if demand and supply both work with maximized agency, and scale in ways that are good for both. That’s the idea behind market intelligence that flows both ways.
Making and maintaining those kinds of relationships will be VRM+CRM, What those together will make are wholes that exceed the sum of either part.
This appears atop a DuckDuckGo search. A few years ago, numbers 1 and 2 would have been down next to number 6.
I wrote a chapter on Agency in The Intention Economy because back then (2012) the word mostly meant an insurance or advertising business. The earlier meaning, derived from the Latin agere, meaning “to do,” had mostly been forgotten.
Now agency is everywhere, and is given fresh meaning with the adjective agentic.
We can thank AI for that. The big craze now is to have AI agents for everything, and to make all kinds of stuff “agentic,” using AI.
Including each of us. We should all maximize our agency with our own personal AI.
With that in mind, and thinking toward upcoming conferences on AI (and our own VRM Day, this coming October 19th ), I just added this section to the VRM Development Work page in our wiki:
Personal AI
Balnce.ai † “Your personal AI, your loyal agents and a network that makes your data work for you.”
Base.org “Base is built to empower builders, creators, and people everywhere to build apps, grow businesses, create what they love, and earn onchain.”
Decentralized AI Agent Alliance “…offers a compelling alternative, giving individuals sovereignty, including ownership of their identity and data.”
Kwaai “a volunteer-based AI research and development lab focused on democratizing artificial intelligence by building open source Personal AI.” Also, KwaaiNet “AI running distributed on a P2P fabric,” now (July 2025) with Verida “Create and deploy personalized AI agents with secure data connectors, custom knowledge bases, and configurable inference endpoints.”
The AI Alliance “building and advancing open source AI agents, data, models, evaluation, safety, applications and advocacy to ensure everyone can benefit.”
Please add more, or make corrections on what’s there. If you don’t have editing privileges, just write to me and I’ll make the changes. Thanks!
Customers need privacy, respect, and the ability to provide good and helpful information to the companies they deal with. The good clues customers bring can include far more than what companies get today from their CRM systems and from surveillance of customer activities. For example, market intelligence that flows both ways can happen on a massive scale.
But only if customers set the terms.
Now they can, using a new standard from the IEEE called P7012, aka MyTerms. It governs machine readability of personal privacy terms. These are terms that customers proffer as first parties, and companies agree to as second parties. Lots of business can be built on top of those terms, which at the ground level start with service provision without surveillance or unwanted data sharing by the company with other parties. New agreements can be made on top of that, but MyTerms are where genuine and trusting (rather than today’s coerced and one-sided) relationships can be built.
When companies are open to MyTerms agreements, they don’t need cookie notices. Nor do they need 10,000-word terms and conditions or privacy policies because they’ll have contractual agreements with customers that work for both sides.
On top of that foundation, real relationships can be built by VRM systems on the customers’ side and CRM systems on the corporate side. Both can also use AI agents: personal AI for customers and corporate AI for companies. Massive businesses can grow to supply tools and services on both sides of those new relationships. These are businesses that can only grow atop agreements that customers bring to the table, and at scale across all the companies they engage.
This is the kind of thing that four guys (me included)† had in mind when they posted The Cluetrain Manifesto* on the Web in April 1999. A book version of the manifesto came out in early 2000 and became a business bestseller that still sells in nine languages. Above the manifesto’s 95 theses is this master clue**, written by Christopher Locke:
MyTerms is the only way we (who are not seats or eyeballs or end users or consumers) finally have reach that exceeds corporate grasp, so companies can finally deal with the kind of personal agency that the Internet promised in the first place.
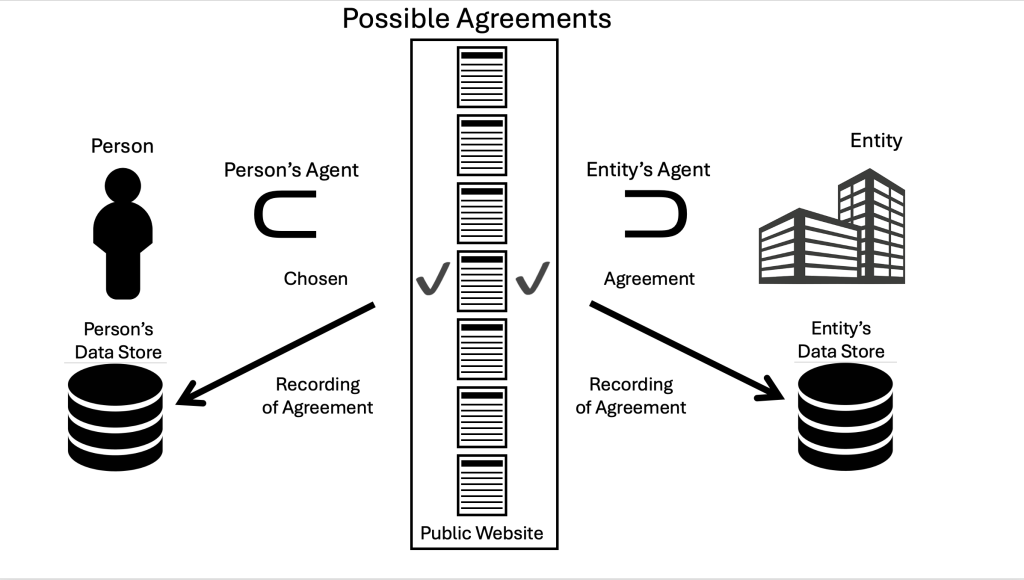
The MyTerms standard requires that a roster of possible agreements be posted at a disinterested nonprofit. The individual chooses one, the company agrees to it (or not). Both sides keep an identical record of the agreement.
The first roster will be at Customer Commons, which is ProjectVRM’s 501(c)3 nonprofit spinoff. It was created to do for personal privacy terms what Creative Commons does for personal copyright licenses. (It was Customer Commons, aka CuCo, that the IEEE approached with the idea of creating the MyTerms standard.)
Work on MyTerms started in 2017 and is in the final stages of IEEE approval process. While it is due to be published early next year, what it specifies is simple:
Individuals can choose a term posted at Customer Commons or the equivalent
Companies can agree to the individual’s choice or not
The decision can be recorded identically by both sides
Data about the decision can be recorded by both sides and kept for further reference, auditing, or dispute resolution
Both sides can know and display the state of agreement or absence of agreement (for example, the state of a relationship, should one come to exist)
MyTerms not a technical spec, so implementations are open to whatever. Development on any of those can start now. So can work in any of the six areas listed above.
The biggest thing MyTerms does for customers—and people just using free services—is getting rid of cookie notices, which are massively annoying and not worth the pixels they are printed on. If a company really does care about personal privacy, it’ll respect personal privacy requirements. This is how things work in the natural world, where tracking people like marked animals has been morally wrong for millennia. In the digital world, however, agreements need to be explicit, so programming and services can be based on them. MyTerms does that.
For business, MyTerms has lots of advantages:
Reduced or eliminated compliance risk
Competitive differentiation
Lower customer churn
Grounds for real rather than coerced relationships (CRM+VRM)
Grounds for better signaling (clues!) going in both directions
Reduced or eliminated guesswork about what customers want, how they use products and services, and how both might be improved
Lawyers get a new market for services on both the buy and sell sides of the marketplace. Companies in the CMP (consent management platform) business (e.g. Admiral and OneTrust) have something new and better to sell.
Lawmakers and Regulators can start looking at the Net and the Web as places where freedom of contract prevails, and contracts of adhesion (such as what you “agree” to with cookie notices) are obsolesced.
Developers can have a field day (or decade). Look for these categories to emerge
Agreement Management Platforms – Migrate from today’s much-hated consent management platforms (hello OneTrust, Admiral, and the rest).
Vendor Relationship Management (VRM) Tools and services – Fill the vacuum that’s been there since the Web got real in 1995.
Customer Relationship Management (CRM) – Make its middle name finally mean something.
Customer Data Return (CDR) – Give, sell back, or share with customers the data you’ve been gathering without their permission since forever. Talking here to car companies, TV makers, app makers, and every other technology product with spyware onboard for reporting personal activity to parties unknown.
Platform Relief – Free customers from the walled gardens of Apple, Microsoft, Amazon, and every other maker of hardware and software that currently bears the full burden of providing personal privacy to customers and users. Those companies can also embrace and help implement MyTerms for both sides of the marketplace.
New dances between customers and companies, demand and supply. (“The Dance” is a closing chapter of The Intention Economy.)
New commercial ecosystems can grow around a richer flow of clues in both directions, based on shared interest and trust between demand and supply.
Surveillance capitalism will be obsolesced — and replaced by an economy aligned with personal agency and respect from customers’ corporate partners.
A new distributed P2P fabric of personally secure and shared data processing and storage — See what KwaaiNet + Verida, for example, might do together.
All aboard!
†Speaking for myself in this post. I invite the other two surviving co-authors to weigh in if they like.
*At this writing, the Cluetrain website, along with many others at its host, is offline while being cured of an infection. To be clear, however, it will be back on the Web. Meanwhile, I’m linking to a snapshot of the site in the Internet Archive—a service for which the world should be massively grateful.
**The thesis that did the most to popularize Cluetrain was “Markets are conversations,” which was at the top of Cluetrain’s ninety-five theses. Imagining that this thesis was just for them, marketers everywhere saw marketing, rather than markets, as “conversations.” Besides misunderstanding what Cluetrain meant by conversation (that customers and companies should both have equal and reciprocal agency, and engage in human ways), marketing gave us “conversational” versions of itself that were mostly annoying. And now (thank you, marketing), every damn topic is now also a fucking “conversation”—the “climate conversation,” the “gender conversation,” the “conversation about data ownership.” I suspect that making “conversation” a synonym for “topic” was also a step toward making every piece of propaganda into a “narrative.” But I digress. Stop reading here and scroll back to read the case for MyTerms. And please, hope that it also doesn’t become woefully misunderstood.
Here’s one graphic from the piece, with its caption:
Illustration of the Rec4Agentverse. The left side depicts three roles in the RecAgentverse: the user, the Agent Recommender, and Item Agents, along with their interconnected relationships. In contrast to traditional recommender systems, the Rec4Agentverse has more intimate relationships among the three roles. For instance, there are multi-round interactions between 1) users and Item Agents and 2) the Agent Recommender and Item Agents. The right side demonstrates how the Agent Recommender can collaborate with Item Agents to affect the information flow of users and offer personalized information services.
With VRM, however, we need our own personal AI agents, and useful data that’s not limited to what’s gathered by surveillance (which we can assume is most if not all of the Information layer).
So I started a conversation with ChatGPT. I’ll divide it into sections:
Who wrote the CACM piece
The state of recommendation science
Who is working on personal AI
How one can get started
Forms of personal data to manage
There’s a lot here. The meat of it, for ProjectVRM purposes, starts in section 3. (The first two are more about what we’re up against.) Please read the whole thing and help us think through where to go with the challenge facing us. As we see in section 3, we do have some stuff on our side.
1. Who wrote the CACM piece
Me:
Can you tell me more about the authors here: https://cacm.acm.org/research/envisioning-recommendations-on-an-llm-based-agent-platform/?
ChatGPT:
🧑💼 Jizhi Zhang
Affiliation: University of Science and Technology of China (USTC), Data Science Lab (inferred from USTC page)cacm.acm.org+14data-science.ustc.edu.cn+14x.com+14. Research Interests: Recommendation systems, LLM-based agent platforms, and interactive intelligent systems—his lead authorship and continued work on Prospect Personalized Recommendation on LLM-Based Agent Platform (arXiv Feb 2024) reinforce thisarxiv.org.
Affiliations: While CACM doesn’t list this, Jizhi Zhang and Fuli Feng are part of USTC’s Data Science Lab; Tat‑Seng Chua is a distinguished researcher from the National University of Singapore known for multimedia and information retrieval. Expertise: A mix of recommender system design, LLM-agent evaluation, multimedia analysis, and human-AI interaction—reflecting a blend of USTC’s strengths and CACM relevancedata-science.ustc.edu.cn+8cacm.acm.org+8data-science.ustc.edu.cn+8linkedin.com+4arxiv.org+4researchgate.net+4.
🧑🎓 Wanhong Xu
Affiliation: USTC Data Science Lab (USTC LDS), contributor to the same article . Role: Emerging researcher whose latest publication is this Rec4Agentverse article, indicating an early-career focus in LLM-based recommender systemslinkedin.com+8data-science.ustc.edu.cn+8linkedin.com+8.
🧠 Broader Context & Contributions
The group operates at the intersection of Large Language Models, agent-oriented systems, and recommender systems, pioneering a Rec4Agentverse paradigm that treats LLM-powered agents as “recommendable” items collaborating with one another—an evolution of traditional recommendation frameworkscacm.acm.org+5cacm.acm.org+5cacm.acm.org+5. Their work continues earlier research (e.g., Prospect Personalized Recommendation… in Feb 2024), solidifying their ongoing commitment to expanding intelligent, conversational recommendation platformsarxiv.org.
🧭 Why This Matters
Academic Thought Leadership: Jizhi Zhang and colleagues are pushing forward thinking about how recommendations can evolve when agents—not passive items—are central. Institutional Backing: All deeply connected to USTC’s Data Science Lab, underscoring strong Chinese academic investment in AI-driven recommender innovation. Collaborative Reach: Including scholars like Tat‑Seng Chua broadens the research to include international perspectives in multimedia and retrieval systems.
In summary: This team is a multidisciplinary cohort—centered at USTC with international collaboration—who are pioneering the idea that LLM agents can become interactive, dynamic items in recommender systems. Their work positions them at the forefront of intelligent agent systems and could reshape how platforms personalize experiences in the future.
If you’re curious about any individual’s past publications, citation impact, or related work (e.g., on Agent4Rec), I’d be happy to dive deeper!
3. The state of recommendation science
Me:
How large is the emerging science, within the AI field, of recommendations?
ChatGPT:
The science of recommendations, particularly within the AI field, is not just emerging—it’s a massive, rapidly evolving subfield that is both academically rich and commercially dominant. That said, it’s also entering a new phase, driven by the rise of large language models (LLMs), interactive agents, and multimodal platforms.
📚 Academic Scope
1. Established Field: Recommender Systems
Recommender systems (RecSys) are a well-developed domain within AI and machine learning, with roots in the 1990s.
Annual conferences like: ACM RecSys (since 2007) SIGIR, KDD, WSDM, and NeurIPS regularly feature recommendation research.
Thousands of papers annually on topics like:
Collaborative filtering
Matrix/tensor factorization
Deep learning for recommendation
Fairness, transparency, and explainability in RecSys
Reinforcement learning and bandit algorithms for personalization
🔎 As of 2024, over 60,000 papers in academic databases (e.g., Google Scholar) are tagged or indexed under “recommender systems”.
📈 Current Trends & Expanding Frontiers
2. LLMs + Recommendation = New Subfield
A major shift is underway: integrating Large Language Models (LLMs) into recommendation systems.
These go beyond “you may also like” to:
Use natural language context and dialogue
Generate explanations, not just rankings
Support conversational recommendation Coordinate agent ecosystems, e.g., multi-agent reasoning environments
Example paradigms:
RecMind – reasoning-aware recommendation agents Rec4Agentverse – treating agents as recommendable entities ChatRecs – integrating LLMs into live user conversations
3. Multimodal & Multitask Integration
Systems increasingly blend text, image, video, behavior, and user feedback.
LLMs allow richer personalization using complex user intent derived from unstructured data.
4. Industry Investment
FAANG companies (especially YouTube, Netflix, Amazon, TikTok, and Spotify) base their core user experience on AI-driven recommendation.
Billions of dollars are spent optimizing:
Ranking quality
Engagement prediction
Real-time inference
Federated and privacy-preserving personalization
Not new, but rapidly evolving Core to AI applications, especially with LLMs and agents One of the most commercially and socially impactful domains in modern AI Growing into new subfields (e.g. Rec4Agentverse, LLM Rec, multi-agent Rec)
Let me know if you’d like a visual map of how the recommendation science ecosystem is structured—or who the top authors and institutions are in this space
3. Who is working on personal AI
Me:
And who, if anyone, is working to provide customers with their own personal AI tools: ones that work for them, to empower their own agency in the marketplace? By which I mean truly personal AI, and not the kind personalized by some external LLM (or similar) system.
ChatGPT:
That’s an essential and forward-looking question—especially as most “AI for you” today really means “AI about you, for someone else.”
While Big Tech firms dominate personalized AI, a growing ecosystem is focused on truly personal AI—that is, AI you own, that works for you (not advertisers or platforms), and that enhances your agency in the marketplace and your life.
Here are the most notable people, projects, and initiatives advancing truly personal AI today:
🧠 1. Kwaai and pAI-OS (South Africa / Global)
Kwaai is building an open-source, user-sovereign personal AI OS called pAI-OS.
Designed to run locally or at user discretion, with full data ownership, modular agent systems, and plugin capability.
Aligns with IEEE P7012 (“MyTerms”) privacy standards (see below).
Actively exploring intentcasting, customer signaling, and VRM (Vendor Relationship Management).
Site: https://kwaai.ai
🛠️ 2. Indie AI and Personal Agent projects
Several smaller open-source initiatives are trying to build personal agent toolkits that you can host and configure:
Examples:
AutoGen Studio (Microsoft) – allows building agent workflows, some of which can be user-defined. But it’s not yet fully personal or private. Langroid – open-source framework for local agent-based LLM systems. Designed for extensibility, can be made personal with effort. OpenDevin, Superagent, Auto-GPT – can be self-hosted, though most are still tool-centric rather than user-centric. Personal.ai – A commercial startup that says it is personal, but uses centralized storage and fine-tuning, so actual user control is limited.
🔍 Reality check: Most of these still rely on external LLMs (like OpenAI or Anthropic), even if they claim to be “your AI”.
🌐 3. Solid Project (by Tim Berners-Lee)
While not AI per se, Solid is a decentralized identity and data storage architecture that allows individuals to store their own data in personal data pods.
AI tools can be layered on top to access only the data you choose to share.
Foundation for personal AI assistants that can work with your data, not on others’ clouds. https://solidproject.org
📜 4. IEEE P7012 – MyTerms
A standard being developed to flip the notice-and-consent regime—so individuals, not companies, dictate the terms of data use.
Backed by Customer Commons and designed to support intentcasting and personal marketplace signaling.
This enables a personal AI to serve as your agent, enforcing your terms and engaging the marketplace on your behalf.
🧩 5. Project VRM (Vendor Relationship Management)
Initiated by Doc Searls to empower customers with tools to manage vendors, not just the reverse.
Envisions personal tools (including AI) to:
Signal intent
Manage service contracts
Retain records of offers, purchases, warranties
Avoid manipulation, surveillance, and lock-in
Project VRM is not a software project per se, but a framework guiding developers to build personal tools that support individual autonomy.
🔒 6. Open-source LLM stacks for local use
Several local LLM projects can be combined with personal data layers to build truly personal AI:
LM Studio – runs local models on desktop PrivateGPT – local inference + local documents Ollama – macOS-native interface for fast-running models like LLaMA, Mistral LangChain / LlamaIndex – frameworks for building RAG systems with local documents
These aren’t personal AI systems yet—but they are key ingredients.
🧭 Summary
Name / Project
What They Do
Status
Kwaai / pAI-OS
Open, personal AI OS and agent platform
Early but active
Solid
Personal data control layer
Stable; in use
IEEE P7012
Standards for user-enforced data terms
In development
Project VRM
Framework for tools that empower buyers
Thought leadership; toolkits emerging
Local AI frameworks
Tech foundations for personal AI
Available, DIY-friendly
🚧 The Gap
Despite this promising landscape, no major platform today delivers a fully integrated, easy-to-use personal AI that you own, configure, and direct—yet. But:
A personal AI revolution is underway, led by privacy advocates, open-source communities, and a few visionary developers—not Big Tech.
Would you like help putting together a DIY stack for your own personal AI toolkit based on this landscape?
Me:
Can you name some of the people in the personal AI revolution, and tell me what that DIY stack would contain?
ChatGPT:
Absolutely. Here’s a breakdown of key people involved in the personal AI movement, followed by a practical DIY stack you can start building today.
👤 People Leading or Advancing the Personal AI Revolution
These individuals aren’t all working on the same projects, but they’re aligned in trying to build AI that’s owned, run, and controlled by the individual—not centralized platforms.
🧑🔬 Tim Berners-Lee
Project: Solid (stewarded by ODI, commercially implemented by companies including TBLs Inrupt) Focus: Decentralized web and personal data ownership via data pods Impact: Infrastructure for privacy-respecting personal AI agents https://solidproject.org
👤 Doc Searls
Project: Project VRM, Customer Commons, IEEE P7012 Focus: Customer empowerment, intentcasting, reversing surveillance capitalism Impact: Philosophy and standards for customer-directed personal AI https://projectvrm.org
🧠 Tawanda Kembo & Kwaai team
Project: pAI-OS (personal AI operating system) Focus: Agent-centric open-source operating system for personal AI Impact: One of the few efforts aiming to create a complete personal AI stack https://kwaai.ai
🧑💻 Simon Willison
Project: Datasette, open tools for data management Focus: Personal data control, lightweight databases, LLM + local tooling Impact: Key figure in the open data + local AI tooling space https://simonwillison.net
🤖 Brian Roemmele
Project: Multiplex (personal voice AI) Focus: Voice-first personal assistants you run locally Impact: Vocal advocate for true personal AI, often referencing “software you own”
🛠️ A DIY Personal AI Stack (2025 Edition)
This stack assumes local-first, modular, privacy-respecting tools. You can mix and match based on your needs.
🧩 Core Components
Layer
Tools / Projects
Notes
1. OS Layer
Linux, pAI-OS (in dev)
Linux gives flexibility; pAI-OS aims to be a full personal AI OS
2. Local LLM Inference
Ollama, LM Studio, PrivateGPT, LocalAI
Run models like LLaMA 3, Mistral, Phi-3 entirely offline
3. Vector Database
Chroma, Weaviate, Milvus, or SQLite with FTS5
Store and retrieve embedded text data
4. Personal Indexing
LlamaIndex, LangChain, AutoGen, GPTPilot
Feed personal documents and data to your LLM
5. Personal Data Storage
Solid POD, Datasette, Obsidian
Your life’s data, structured and queryable
6. Personal Agent Framework
Superagent, CrewAI, Langroid, AutoGen
Design agents that act on your behalf, modular and scriptable
7. Front-end Interface
Gradio, Streamlit, Tauri app, Electron
Local GUI/UX to interact with your agent
8. Voice Interface (optional)
OpenVoice, Vosk, Whisper.cpp, Coqui TTS
Build voice-in/voice-out agent on your machine
🧠 Optional Add-ons
Offline search: Chat over your files, PDFs, photos, and emails with LlamaIndex + PrivateGPT Calendar/notes: Sync with Obsidian or local markdown-based knowledge base Browser agent: Auto-control browser via Puppeteer/Playwright for marketplace navigation
🧭 What’s Still Missing?
True personal OS integration (like what pAI-OS is trying to do)
Seamless data portability and contract enforcement (IEEE P7012 is working on it)
Trusted personal AI app ecosystem (some apps, like Beeper or Obsidian, are getting close)
Would you like a tailored recommendation for building a personal AI stack based on your technical skill level or use cases (e.g., journaling, research, negotiation, shopping, data querying)?
4. How can I get started?
Me:
Yes. My technical skill level is modest at best. I can write HTML and do very basic stuff in the command line. I have an extra laptop I can devote to solo work, and Ethernet to a 2.1GB/s symmetrical fiber connection to the Internet with no data limits.
ChatGPT:
Great — with your setup (modest technical skills, spare laptop, blazing-fast fiber), you’re in an excellent position to begin building a practical personal AI system without diving too deep into complex dev work. Here’s a recommended stack tailored to your current skills and goals:
🧰 YOUR PERSONAL AI STARTER STACK (2025)
🔧 1. Platform Base
Use a Linux distribution designed for ease of use and AI tinkering:
Recommended: Pop!_OS or Ubuntu 24.04 Easy GUI, good hardware compatibility, lots of online support
Optional: Use your laptop in “air-gapped” mode for privacy and full local control
🤖 2. Run a Local LLM with LM Studio
LM Studio (macOS/Windows/Linux) lets you run LLaMA 3, Mistral, Phi-3, and others without coding.
Built-in UI — chat with models locally, no internet required after download.
You can download 7B or 13B models based on your hardware.
Best for: private journaling, summarizing files, answering questions.
✅ Why it’s ideal for you:
GUI-based
Just click and download models
No API keys or command-line needed once installed
📁 3. Chat with Your Files (PrivateGPT / LlamaIndex)
PrivateGPT or GPTPilot can let you ask questions across PDFs, emails, and notes stored on your machine.
Start simple: drop files into a folder, let the AI index them. Optionally install via Docker (one command), or use their prebuilt apps.
✅ Use case:
“Summarize this research PDF”
“What did I write about project X last month?”
“Find the email where someone mentioned a refund”
📚 4. Knowledge Base + Journaling with Obsidian
Obsidian = Markdown-based knowledge base.
Everything you write stays local.
You can point LM Studio to your notes to query your own memory.
✅ Easy way to:
Keep private journals
Index your life
Ask your AI things like “What are my goals for June?”
🗂️ 5. Personal Data Management with Datasette
Datasette by Simon Willison lets you browse and query your own data with simple SQL and CSV files.
Feeds AI with structured personal info (purchases, inventory, plans, etc.)
You can install it with a single terminal command:
bash pip install datasette datasette serve your-data.db datasette serve your-data.db
✅ Combine with LM Studio to get responses like:
“What subscriptions do I need to cancel?”
“When did I last back up my photos?”
Use AutoBrowser or a simpler Puppeteer script to automate browsing tasks (like checking prices, news, account activity).
Start with prebuilt scripts. No coding needed if you copy/paste working examples.
🔒 7. Privacy Boosters
Run Tailscale or WireGuard to access your AI remotely if needed.
Use LocalAI or Ollama if you later want to run everything without GUI (more advanced).
🧭 Putting It All Together
Task
Tool
Chat privately with an AI
LM Studio
Summarize your own notes or PDFs
PrivateGPT or GPTPilot
Store and reflect on your life data
Obsidian, Datasette
Manage subscriptions and tasks
Datasette + Chat
Ask about your files or history
LlamaIndex or GPT over Obsidian notes
Use voice later (optional)
Whisper.cpp, OpenVoice (easy tools)
🪜 Next Steps (in plain order)
Install Pop!_OS or Ubuntu on your spare laptop
Install LM Studio and download a 7B model like Mistral or LLaMA 3 Start using it to answer personal questions and summarize documents
Add Obsidian to start journaling and reflecting
Try PrivateGPT or Datasette to search your past or track your life
Would you like a checklist or an install script to get started with this stack? I can also help you set up a file structure to begin tracking and querying your own data.
5. Forms of personal data to manage
Me:
The personal data I need to manage are health records (from 20-plus providers), financial records (fewer than health), travel records (including the kind kept by apps that watch my movements), subscriptions and other recurring payments, shows I have watched and on what channels or services (data gathered by my Samsung and Roku TVs and presumably shared with others but to which I don’t yet have access), continuing work and work history with various clients and employers, contacts, archival and current calendars, real estate, personal items bought or acquired from various sources and where they are kept or stored, and business dealings. What would be the file structure for all that, and how would I manage it? Note that I am not talking about shopping yet; that’s a separate concern.
ChatGPT:
Thanks for the detailed breakdown — you’re describing the foundation of a true personal data architecture: structured, queryable, and under your control. Let’s build you a file structure and management strategy that matches your needs without overcomplicating the tech.
📁 Recommended Top-Level Folder Structure
This folder structure is designed to be future-proof, machine-readable, and human-usable. Use plain folders, CSV/JSON/Markdown files, and optional SQLite databases to store structured data. You can later layer tools (like LLMs or Datasette) on top.
Use Obsidian for ongoing notes (e.g. travel journal, work logs)
Use Paperless-ngx (optional) to OCR and tag your scanned PDFs (health, finance)
Use GPS History Export from Google and Apple for travel/locations
Use email filters or Zapier to auto-download bills, statements, confirmations
4. Querying and Reviewing
Add one or more of these later:
Datasette → browse and search CSVs/SQLite locally
LM Studio + PrivateGPT → ask, “When did I last visit Dr. Chen?” or “What devices are in storage?”
LlamaIndex → index your file tree and let AI search/summarize it
✅ Summary of Benefits
Goal
This Setup Delivers
Total local control
You decide access, storage, retention
Future AI-readiness
Structured enough for agents to use
Easy to back up
Plain files, portable databases
Modular growth
Start simple, layer in AI when ready
Would you like me to generate a starter template with folder structure and some CSV/Markdown file formats filled in with mock data for each domain? That way you can load it directly into your system and start customizing.
Me again:
That’s it for now.
What should my next request be, or what other direction would you like me (or us) to take this?
Or, what are the learnings we have so far in this field that barely exists?
Oh, and excuse whatever inaccuracies ChatGPT may have floated above. Or give me fixes.
Thanks.
*The links are mine and based on searches for those names. I might have some of them wrong, however, since searches for those names bring up many scholars with the same names. And, while each name had a link, they all went to an author archive page that was absent (with one exception) of other contributions to the publication.
Hmm… maybe The Independent Customer should be the title of my follow-up to The Intention Economy.
Because, to have an Intention Economy, one needs independent customers: ones who are in charge of their own lives in the digital world:
Who they are—to themselves, and to all the entities they know, including other people, and organizations of all kinds, including companies.
What they know about their lives (property, health, relationships, plans, histories)—and the lives of others with whom they have relationships.
Their plans—for everything.: what they will do, what they will buy, where they will go, what tickets they hold, you name it.
Add whatever you want to that list. It can be anything. Eventually it will be everything that has a digital form.
What will hold all that information, and what will make that information safely engageable with other people and entities?
A wallet.
Not a digital version of the container for cash and cards we carry in our purses and pockets. Apple and Google think they own that space already, which is fine, because that space is confined by the mobile app model. Wallets will be bigger and deeper than that.
Wallets will embody two A’s: archives and abilities. Among those abilities is AI: your AI. Personal AI. One that is agenticfor you, and not just for the sellers of the world.
Wallets are how we move e-commerce from a world of accounts to a world of independent customers with personal agency. With AI agents working for them and not just for sellers.
The Web3 crowd say digital wallets are about transferrable digital assets and ownership without a central authority. And they are right.
But there’s more.
Many payments and identity experts will say that digital wallets are really about identity. Proving who you are and what you are entitled to do (tickets, access). Maybe even with fancy selective disclosure features.
They are also right. But that’s not the whole picture.
A pioneering group of others believe that digital wallets are really about the portability of any verifiable information, and digital authenticity.
And they too are right. We’re now getting much, much closer to what I’m talking about. But there’s still more.
Once individuals can show up independently, with their own digital tools – digital wallets with verifiable, data, identity and digital assets – then we have something new, something special.
It’s a New. Customer. Channel.
Once a business asks for some data from a customer’s digital wallet, they have the opportunity to form a new digital connection with that customer.
A persistent one.
A verifiable one.
A private one.
An auditable, secure and intelligent one.
My goodness, what business wouldn’t want that? Imagine plugging that customer connection directly into business systems and processes, like CRM.
Yes, digital wallets can hold and manage assets. And identity. And portable, verifiable, authentic data.
But with the narrower ‘data and assets’ framing, we risk missing the larger market opportunity.
Digital wallets become the new account.
For everything.
OK so what is an account?
With money, it’s a shared and trusted record of all your transactions. Who did what, who paid what, and who owes who.
With business, it’s a shared record of all your products and interactions. It’s a critical customer channel and interface. The place people come to check things. To ask things. To ‘do business’.
Each customer account has a number. A unique identifier. It has a way to message customers. A way to record what’s been sent to, and received from, the customer.
Ring a bell?
Digital wallets will be able to do all this and much more.
They will also be more secure. More private. More flexible. And more portable.
So it’s possible – I’d even argue more likely – that digital wallets may be more disruptive than browsers were in the 1990s.
But like browsers, they will first be misunderstood.
Digital wallets will become the new account.
For business? For government? For banking? For health? For travel?
For life.
I have said for over a decade that the only 360° view of the customer, is the customer.
Just imagine, once a customer can bring their own wallet – their own account – to each business:
The economics change. Why would a business maintain a complex and proprietary account platform when digital interactions can be handled – indeed automated – via a verifiable digital wallet that’s available on every smart device?
The data flows change. Why would a business store unnecessary customer data when they can just ask for it on demand, with consent, from the customer’s digital wallet? Then delete it again once used?
The risks change. What if we could reduce fraud and account takeover to near zero, when every customer interaction has to be authenticated via the customer’s digital wallet (likely with biometrics)?
The very fabric of the customer relationship changes.
This is just a glimpse of what‘s possible, and what’s coming. Especially when you tie it to digital AI agents….
When you look closely, you’ll see that digital wallets aren’t even The Thing. They are ‘below the surface’ of the customer channel.
Lots to be written about that. Coming soon.
For now, it’s a simple switch: when you hear ‘account’, just think ‘wallet’.
Here is the challenge: making wallets a must-have: an invention that mothers necessity.
We’ve had those before, with—
PCs
word processors and spreadsheets
the Net and the Web,
graphical browsers
personal publishing and syndication
smartphones and apps
streams and podcasts.
Wallets need to be like all of those: must-haves that transform and not just disrupt.
It’s a tall order, but—given the vast possibilities—one that is bound to be filled.
As for why this won’t be something one of the bigs (e.g. Apple and Google) do for themselves, consider these five words you hear often online:
The cover page of the Weekend Review section of The Wall Street Journal, July 20, 2012
On July 9, 2012, not long after The Intention Economycame out, I got word from Gary Rosen of The Wall Street Journal that the paper’s publisher, Robert Thomson, loved the book and wanted “an excerpt/adaptation” from the book for the cover story of the WSJ’s Weekend Review section. The image above is the whole cover of that section, which appeared later that month.
In the article I described a new way to shop:
An “intentcast” goes out to the marketplace, revealing only what’s required to attract offers. No personal information is revealed, except to vendors with whom you already have a trusted relationship.
I also said that this form of shopping—
…can be made possible only by the full empowerment of individuals—that is, by making them both independent of controlling organizations and better able to engage with them. Work toward these goals is going on today, inside a new field called VRM, for vendor relationship management. VRM works on the demand side of the marketplace: for you, the customer, rather than for sellers and third parties on the supply side.
The scenario I described was set ten years out: in 2022, a future now two years in the past. In the meantime, many approaches to intentcasting have come and gone. The ones that have stayed are Craigslist, Facebook Marketplace, Instacart, TaskRabbit, Thumbtack, and a few others. (Thumbtack participated in the early days of ProjectVRM.) We include them in our list of intentcasting services because they model at least some of what we’d like intentcasting to be. What they don’t model is the full empowerment of individuals as independent actors: ones whose intentions can scale across whole markets and many sellers:
Scale gives the customer single ways to deal with many companies. For example, she should be able to change her address or last name with every company she deals with in one move—or to send an intention-to-buy “intentcast” to a whole market.
Should we call the sum of it “i-commerce“? Just a thought.
Back to the Wall Street Journal article. It is clear to me now that The Customer as a God would have been a much better title for my book than The Intention Economy, which needs explaining and sounds too much like The Attention Economy, which was the title of the book that came out ten years earlier. (I’ve met people who have read that one and thought it was mine—or worse, called my book “The Attention Economy” and sent readers to the wrong one.)
Of course, calling customers gods is hyperbole: exaggeration for effect. VRM has always been about customers coming to companies as equals. The “revolution in personal empowerment” in the subhead of “The Customer as a God” is about equality, not supremacy. For more on that, see the eleven posts before this one that mention the R-button:
That symbol (or pair of symbols) is about two parties who attract each other (like two magnets) and engage as equals. It’s a symbol that only makes full sense in open markets where free customers prove more valuable than captive ones. Not markets where customers are mere “targets” to “acquire,” “capture,” “manage,” “control” or “lock in” as if they were slaves or cattle.
The stage of Internet growth called Web 2.0 was all about those forms of capture, control, and coerced dependency. We’re still in it. (What’s being called Web3 is, while “decentralized” (note: not distributed), it is also based on tokens and blockchain. ) Investment in customer independence rounds to nil.
And that’s probably the biggest reason intentcasting as we imagined it in the first place has not taken off. It is very hard, inside industrial-age business norms (which we still have) to see customers as equals, or as human beings who should be equipped to lead in the dance between buyers and sellers, or demand and supply, in truly open marketplaces. It’s still easier to see us as mere consumers (which Jerry Michalski calls “gullets with wallets and eyeballs”).
So, where is there hope?
How about AI? It’s at the late end of its craze stage, but still here to stay, and hot as ever:
Some of us here are working at putting AI on both sides of intentcasting ceremonies. If you have, or know about, one or more of those approaches (or any intentcasting approaches), please share what you know, or what you’re got, in the comments below. And come to VRM Day on October 28. I’ll be putting up the invite for that shortly.
What forms of pAI—personal AI—are Apple, Mozilla, Google, Meta, Microsoft and the rest not doing?
Let’s look at those first two because they’re at the top of the news LIFO buffer.
Apple Intelligence (“coming in beta this fall*“), announced yesterday, will help you with writing and creating images while giving you less lame answers from Siri. (Which they should re-name. Siri is Apple’s Clippy.) It “can draw on larger server-based models, running on Apple silicon, to handle more complex requests for you while protecting your privacy.” The “larger models” will be white-labeled ChatGPT, plus Apple’s own small language models (SLMs).
This program is designed to empower independent AI and machine learning engineers with the resources and support they need to thrive. It aims to cultivate a more innovative AI ecosystem, and it’s one of Mozilla’s key initiatives to make AI meaningfully impactful — alongside efforts like Mozilla.ai, the Responsible AI Challenge and the Rise25 Awards.
The Mozilla Builders Accelerator’s inaugural theme is local AI, which involves running AI models and applications directly on personal devices like laptops, smartphones, or edge devices rather than depending on cloud-based services…
We chose Local AI as the theme for the Accelerator’s first cohort because it aligns with our core values of privacy, user empowerment, and open source innovation. This method offers several benefits including:
Privacy: Data stays on the local device, minimizing exposure to potential breaches and misuse.
Agency: Users have greater control over their AI tools and data.
Cost-effectiveness: Reduces reliance on expensive cloud infrastructure, lowering costs for developers and users.
Reliability: Local processing ensures continuous operation even without internet connectivity.
Looks to me like both of these are Big AI writ small. It’s “local,” not personal. It’s made to serve your needs with what BigAI offers through APIs. It is still essentially AIaaS (AI as a Service), rather than truly personal AI (pAI): personalized more than personal.
That’s also what I see when I read between the lines at Mozilla’s AI job openings. Take platform engineer. This person will (among other things), “assist in managing and orchestrating workloads across multiple cloud providers.” That’s fine. I’m sure true pAIs will do that too. But most of pAI will be more personal than that. It will deal with the mundanities of your everyday life. Not with coughing up answers that can only come from AIaaSes.
The problem with personalizing AI giant offerings is that they are large language models (LLM) trained on everything that can be crawled on the Internet, plus who knows what else. Not on your truly personal stuff. This is why “prompt engineering” worthy of the noun is ” not for anybody:
Prompt engineering is crucial for deploying LLMs but is poorly understood mathematically. We formalize LLM systems as a class of discrete stochastic dynamical systems to explore prompt engineering through the lens of control theory. We investigate the reachable set of output token sequences $R_y(\mathbf x_0)$ for which there exists a control input sequence $\mathbf u$ for each $\mathbf y \in R_y(\mathbf x_0)$ that steers the LLM to output $\mathbf y$ from initial state sequence $\mathbf x_0$. We offer analytic analysis on the limitations on the controllability of self-attention in terms of reachable set, where we prove an upper bound on the reachable set of outputs $R_y(\mathbf x_0)$ as a function of the singular values of the parameter matrices. We present complementary empirical analysis on the controllability of a panel of LLMs, including Falcon-7b, Llama-7b, and Falcon-40b. Our results demonstrate a lower bound on the reachable set of outputs $R_y(\mathbf x_0)$ w.r.t. initial state sequences $\mathbf x_0$ sampled from the Wikitext dataset. We find that the correct next Wikitext token following sequence $\mathbf x_0$ is reachable over 97% of the time with prompts of $k\leq 10$ tokens. We also establish that the top 75 most likely next tokens, as estimated by the LLM itself, are reachable at least 85% of the time with prompts of $k\leq 10$ tokens. Intriguingly, short prompt sequences can dramatically alter the likelihood of specific outputs, even making the least likely tokens become the most likely ones. This control-centric analysis of LLMs demonstrates the significant and poorly understood role of input sequences in steering output probabilities, offering a foundational perspective for enhancing language model system capabilities.
But all that stuff applies mostly when we’re prompting a big LLM system.
What about using AI in our own lives, where the data that matters most are in our calendars, contacts, financial and health records, our travels, our correspondence (email, chat, whatever)? And how about all the location data we might get from our cars, phone apps, and phone companies? These should be much easier for a pAI to gather, examine, and help us do useful things. Caring about much less data also means a pAI will be less likely to give wrong (hallucinated) answers.
Today the mental frame almost everybody uses for AI is the Big kind, ingesting everything they can get their crawlers on, and munching all of it in giant compute farms. Those systems are great for lots of stuff, but they still don’t deal with personal data listed in the last paragraph.
Not yet, anyway.
Look at it this way. For each of us, there are three data pools:
The entire Net, which is what gets crawled by all the giant LLM operators, plus whatever else they can get their claws on.
One’s personal life, some of which is digitized in useful form (contacts, calendar, mail, stuff in folders inside PCs and attached drives).
Tell us who is working on what there, preferably with open source, and not sitting on walled garden silicon.
[Later… ] Since readers told me I had small language models (SLMs) wrong in one of the paragraphs above, and I’m not sure I had them right, I rewrote them out of the piece. I invite readers to post comments to further correct and expand on the subject of pAIs and what they can do.
Are they going to shake hands or fight? We’ll answer that question after personal AI exists and operates as a powerful personal agent.
You’re reading this on a machine with an operating system: Linux, Windows, MacOS, iOS, or Android.
But that’s not your OS. It’s your machine’s.
How about one for you, that runs on your machine but is entirely yours? Let’s call it a Personal OS, or a POS.
The POS will have a kernel onto which abilities (not just applications) can be added. An extreme example of how this might work is Neo learning ju jitsu in The Matrix:
That OS amplified Neo’s own intelligence, in his own head. We’re far from that today. But we can at least add abilities to a POS of our own. Those too can give us more agency of many kinds.
To my knowledge, there is only one POS so far. It’s called pAI-OS (Github code), and it’s led by Kwaai.* To my knowledge, pAI-OS is the first and only truly personal operating system. (If others do the same, let me know and I’ll talk those up too.) And it is built to run our own AIs. Let’s call them PAIs, where the A can mean amplified or augmented (sourcing Doug Englebart for the latter).
So, what kind of abilities are we talking about?
Let’s start with something that could hardly be more mundane and important: memory.
In Laws of Media, Marshall McLuhan (five decades ago) said that computing promises “perfect memory—total and exact.” For many millennia, our species has been outboarding memory through speech, and the written word, and collecting all of that in libraries and museums. And now, in the digital age that dawned with microcircuits and the Internet, we now occupy a digital world where everybody can publish whatever they want. To peruse that, we made search engines. Those ruled from the late ’90s until approximately yesterday, when AIs took over servicing our interest in answers to questions. Google, Microsoft, ChatGPT, Perplexity.ai, and others have moved into a space we might call AI answerware.
Running all that answerware are corporate AIs. Let’s call them CAIs. Nothing wrong with CAIs, but also nothing personal, because they are not ours. I explain the difference in Personal vs. Personalized AI. Here’s a graphic from that post showing a bit of what abilities might run on your PAI:
PAIs can extend our own memories by accumulating personal stuff we need to know better, and our ability to meet, access, and use the external abilities of the CAI world. So we’ll have our agents + their agents, working together.
For an example of how that might work, take a look at The most important standard in development today: P7012: Standard for Machine Readable Personal Privacy Terms, which “identifies/addresses the manner in which personal privacy terms are proffered and how they can be read and agreed to by machines.” After seven years with a working group, it is now in the IEEE editing and approval mill, edging toward becoming a finished standard by next year. It works like this:
Here your agent (a PAI, represented by the ⊂ symbol) proffers your privacy terms (here is one example) to a corporate agent (which might or might not be a CAI, but is still represented with the reciprocal symbol ⊃. (This should be familiar to ProjectVRM veterans as the r-button. We may finally get to use it!)
The ceremony here is the exact reverse of what we have today with the cookie popovers on most website home pages. This can and should be done ⊂ to ⊃. So should signing and recording the agreement, or the choice of the site, should it tell you to screw off. (An agent running on your PAI will record that diss.)
(a) Consent: the individual has given clear consent for you to process their personal data for a specific purpose.
(b) Contract: the processing is necessary for a contract you have with the individual, or because they have asked you to take specific steps before entering into a contract.
By now everyone knows that (a) Consent has failed. It’s an expensive and meaningless dance, with high cognitive (mostly cynical) overhead, and almost no accountability. Now they’re ready for (b) Contract, especially in ceremonies where the individual (not a mere “user”) takes the lead.
I believe there is less limit to what each of us can do with a PAI than there is to what we can do with a laptop or a phone. Because our PAI is our own. It runs on a deeper machine OS, but is not limited by that. Your PAI, running on your POS, may prove to be the first truly personal layer ever put on a machine OS.
*Full disclosure: I am now the Chief Intention Officer there. At this stage, it’s a voluntary position.
Prompt: A woman uses personal AI to know, get control of, and put to better use all available data about her property, health, finances, contacts, calendar, subscriptions, shopping, travel, and work. Via Microsoft Copilot Designer, with spelling corrections by the author.
Most AI news is about what the giants (OpenAI/Microsoft, Meta, Google/Apple, Amazon, Adobe, Nvidia) are doing (seven $trillion, anyone?), or what AI is doing for business (all of Forbes’ AI 50). Against all that, personal AI appears to be about where personal computing was in 1974: no longer an oxymoron but discussed more than delivered.
For evidence, look up “personal AI.” All the results will be about business (see here and here) or “assistants” that are just suction cups on the tentacles of giants (Siri, Google Assistant, Alexa, Bixby), or wannabes that do the same kind of thing (Lindy, Hound, DataBot).
There may be others, but three exceptions I know are Kin, Personal AI and Pi.
Personal AI is finding its most promoted early uses on the side of business more than the side of customers. Zapier, for example, explains that Personal AI “can be used as a productivity or business tool.”
Kin and Pi are personal assistants that help you with your life by surveilling your activities for your own benefit. I’ve signed up for both, but have only experienced Pit,” or “just vent,” when I ask it to help me with the stuff outlined in (and under) the AI-generated image above, it wants to hook me up with a bunch of siloed platforms that cost money, or to do geeky things (PostgreSQL, MongoDB, Python on my own computer. Provisional conclusion: Pi means well, but the tools aren’t there yet. [Later… Looks like it’s going to morph into some kind of B2B thing, or be abandoned outright, now that Inflection AI’s CEO, Mustafa Suleyman is gone to Microsoft. Hmm… will Microsoft do what we’d like in this space?]
Open source approaches are out there: OpenDAN, Khoj, Kwaai , and Llama are four, and I know at least one will be at VRM Day and IIW.
So, since personal AI may finally be what pushes VRM into becoming a Real Thing, we’ll make it the focus of our next VRM Day.
As always, VRM Day will precede IIW in the same location: the Boole Room of the Computer History Museum in Mountain View, just off Highway 101 in the heart of Silicon Valley. It’ll be on Monday, 15 April, and start at 9am. There’s a Starbucks across the street and ample parking because the museum is officially closed on Mondays, but the door is open. We lunch outdoors (it’s always clear) at the sports bar on the other corner.
You can also just show up, but registering gives us a rough headcount, which is helpful for bringing in the right number of chairs and stuff like that.
We believe that AI will be about individual empowerment and agency on a scale we’ve never seen before
Whoa! That’s what we’ve been working toward here at ProjectVRM since 2006. It’s what John Battelle called for last April:
Imagine a GPT chatbot that you own, trust, and control. Let’s call it a genie, because honestly, that’s the most appropriate word for this new entity. This genie has access to everything you do on your phone, your computer, and sure, why not – your Alexa, your car, basically every digital surface with which you interact. Imagine it’s bounded by immutable rules that state you and you alone can tell it what to do, what information to share, what services to connect to, on what terms, and so on. Now imagine you can ask that genie to perform all manner of magic on your behalf – pretty much any question you can think of, it will figure out an answer.
Genie is good. Dare we try riffing off what Sam said, with IEASWNSB? (Pronounced “Eewasnib,” perhaps?) We might have better luck with that than we’ve had with VRM, Me2B, and other initialisms and acronyms.
For fun, I asked Bing Image Create, which uses OpenAI’s DALL-E to produce images, to make art with its boss’s words. It gave me the images above. Here’s the link.
Those are a little too Ayn Randy for me. So I tried just “Empowered individuals,” and got this—
—which is the Ayn Rand translated to Woke.
But never mind that. Let’s talk about individual empowerment with AI help. Here’s my personal punch list:
Health. Make sense of all my health data. Suck it in from every medical care provider I’ve ever had, and help me make decisions based on it. Also, help me share it on an as-needed basis with my current providers. (On my own terms, about which more below.)
Finances. Pull in and help me make sense of my holdings, obligations, recurring payments, incomes, whatever. Match my orders and shipments from Amazon and other retailers with the cryptic entries (always in ALL CAPS) on my credit card bills. I want to run every receipt I collect through a scanner that does OCR for my AI, which will know what receipt is for what, where it goes in the books it helps me keep, and yearly helps me work through my taxes. The list can go on.
Property. What have I got? I want to point my phone camera at everything that a good AI can recognize, and make sense of all that too. Know all the books on my shelves by reading their spines. Know my furniture, the stuff in my basement. Help me keep records of my car’s history after I give it the VIN number I photographed under the windshield, and run all the records I’ve kept in the glove box through the same scanner I mentioned above. Whatever. Why not?
Correspondence. I have half a million emails here, going back to 1995. (Wish it went back farther.) Lots of texts too, in lots of systems. Help me do a better job of looking back through those than my various clients do. Help me cross-reference those with events I attended and other stuff that may be relevant to some current inquiry.
Contacts. Who do I have in my various directories? How many entries are wrong in one way or another? Go through and correct them, AI butler, using whatever clever new algorithm works for that, supplied by corporate entities whose knowledge of me remains as close to zero as I allow.
Calendar. Tell me where I was on a given day, what I was doing, and who I was with. Knowing all that other personal data (above) will help too.
Business relationships. Look into all my subscriptions and help me fight the fuckery behind nearly all of them. Make better sense of all the “loyalty” programs I’m involved with, and help me unfuck those too since most of them are about entrapment rather than real loyalty. (Bonus links here and here.)
Other involvements. What associations do I belong to? How deeply am I involved with any or all of them? Can we drop some? Add some? Have some insights into how those are going, or should go?
Travel. I have 1.6 million miles with United Airlines alone. Where did I go? When? Why? What did I pay? Are there ways to improve my relationships with airlines and other entities (e.g. car rental agencies, Uber/Lyft, Airbnb, cruise lines)? Are there ways I can help them that don’t require enduring yet another of those annoying surveys that seem to follow every contact with them?
Shopping. We’ve been talking about (and working toward) intentcasting since the late aughts, with lots of developers on the case, but not big breakthroughs. But with AI it’s easy to imagine countless possibilities that begin with one’s intent to buy rather than retailers’ intent to sell. Words to wise sellers: A) Make it as easy as possible for customers’ personal and privacy-guarding AI agents to find what you’ve got and know as much about it as possible, and B) Fire every marketer and marketing system that wants in any ways to trap, milk, coerce, and otherwise fuck over customers. Meanwhile, customers should have AI capacities that keep them from getting screwed, to know when the screwing happens, and to help do something about it.
My own personal data collection. There have been many of these, by many names, tried over the years. The current leading candidate (IMHO) is Sir Tim Berners-Lee‘s Solid project.
John Battelle (see above) adds,
How about remembering the password you used once to log into your healthcare provider three years ago? How about negotiating a way better deal with that service by threatening to move to competitors? Done! Once you’re happy with that healthcare provider, can you ask your genie to file all your claims and make sure you get reimbursed by checking your bank statements? Why yes you can! Your wish has been granted!
Our lives are packed with too much data for our meat brains alone to comprehend fully and put to use. AI is good for that. So bring it on.
And don’t bet that any of the bigs, including OpenAI, will give you anything on the punch list above*. They’re too big, too centralized, too stuck in a mainframe paradigm. They look for what only they can do for you, rather than what you can do for yourself—or do better with your own damn AI.
Personal AI today is where personal computing was fifty years ago. We don’t yet have the Apple II, the Osborne, the TRS-80, the Commodore PET, much less the IBM PC or the Macintosh. We just have big companies with big everything and hooks for developers.
Real personal AI is a huge greenfield. Going there is also, to switch metaphors, a blue ocean strategy. Wrote about that here.
*Except by pouring all that data into their LLM. Not yours.