With gratitude to the famous Peanuts cartoon. (And art help from ChatGPT.)
The EU’s new Digital Omnibus proposal aims to update and expand the GDPR, notably with Article 88b, which includes this:
A new Article 88b Regulation (EU) 2016/679 (General Data Protection Regulation), for automated and machine-readable indications of individual choices and respect of those indications by website providers once standards are available.
That was written in June 2025. (I’ve boldfaced the phrases that matter.) We now have a standard for exactly what the EU wants and needs: IEEE 7012-2025—Standard for Machine-Readable Personal Privacy Terms. It is nicknamed MyTerms (much as IEEE 802.11 is nicknamed Wi-Fi) and was published by the IEEE in January 2026 after nine years in the making. Here’s the PDF.
Article 6 of the GDPR lists six bases for the Lawfulness of Processing:
- the data subject has given consent to the processing of his or her personal data for one or more specific purposes;
- processing is necessary for the performance of a contract to which the data subject is party or in order to take steps at the request of the data subject prior to entering into a contract;
- processing is necessary for compliance with a legal obligation to which the controller is subject;
- processing is necessary in order to protect the vital interests of the data subject or of another natural person;
- processing is necessary for the performance of a task carried out in the public interest or in the exercise of official authority vested in the controller;
- processing is necessary for the purposes of the legitimate interests pursued by the controller or by a third party, except where such interests are overridden by the interests or fundamental rights and freedoms of the data subject which require protection of personal data, in particular where the data subject is a child.
I’ve boldfaced the three that matter, and italicised their core distinctions.
The entire adtech business relies on the first and last of these, consent and legitimate interests, as their excuses for tracking people, allowing them to obey the letter of the GDPR while screwing its spirit.
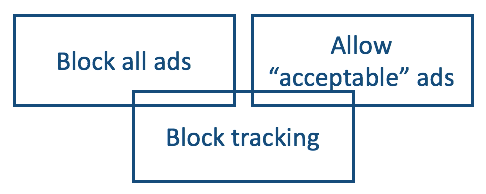
We see consent at work with every cookie notice we click on or click past. And we have no faith that clicks on consent “choices” provide any privacy protection at all. Reasons:
- Most sites ignore cookie choices.
- Many sites set cookies even before a cookie choice is made.
- It’s obvious that adtech is a personalised guesswork business that relies on surveillance, so most of these “choices” are misdirections away from corporate hunger for personal data.
- We have no record of the “choices” we make (and in many cases, no choice is offered), or any way to audit or dispute compliance.
- Uninvited and unwanted surveillance is by now so far out of control that cars, TVs, and AI chatbots are all in on the game (and hardly bother with consent notices).
The legitimate interests are advertising and surveillance, which Google, Facebook and the IAB say the world needs, because it funds so much of what happens online.
To the adtech business, personal privacy is a bug, not a feature. The whole business is incentivised to violate privacy, because violating privacy pays. No amount of regulatory oversight will fix that. To adtech, paying fines for privacy violations is just a cost of doing business.
The only fix that will work is what people—customers and citizens—bring to the market’s table. With MyTerms, they can do that.
MyTerms addresses the second of the GDPR’s six legal bases: contract. Put simply, here is what the MyTerms standard says:
- The person (not a mere data subject) is the first party, and the site or service is the second party.
- The person proffers a contractual agreement chosen from a limited roster posted on the public website of a disinterested nonprofit, such as Customer Commons (which was created to do for personal contracts what Creative Commons does for personal copyrights—and which the IEEE approached with the idea for making MyTerms a standard).
- When the second party agrees, both parties keep an identical record, which supports compliance auditing and dispute resolution. (By preserving evidence, this also creates an infrastructure for dispute avoidance as well.)
The GDPR succeeded by recognising natural persons as holders of rights, but it left intact the industrial age convention in which organisations are the exclusive originators of terms at scale. That’s one reason why persons have remained mere data subjects rather than contractual parties.
Fortunately, the Internet’s base protocols are peer-to-peer. Treating people on the Net as mere “users” and “data subjects” limits their agency. With MyTerms, people acquire a status they yielded when industry won the industrial revolution. (Before the industrial age, surnames—Baker, Müller, Weaver, Lefebvre, Smith, Marchand, Farmer—signified agency: what people did in the world. That’s just one thing we lost when we became workers, executives, consumers, and users.)
In the natural world, privacy is maintained mostly by tacit agreements. In the digital world there is no tacit, so agreements must become explicit and programmable. This is why contracts are the only way we’ll get real personal privacy in the digital world.
It should also be clear by now that polite requests also don’t work. We tried that with Do Not Track, and by the time it finished failing, the adtech lobby had turned it into Tracking Preference Expression—as if we wanted to be tracked all along.
That main pro-consent lobby is the Interactive Advertising Bureau, or IAB. Among its recommendations for the Digital Omnibus are deleting 88b and improving consent in various ways, such as “Revise the proposed stricter consent rules.”
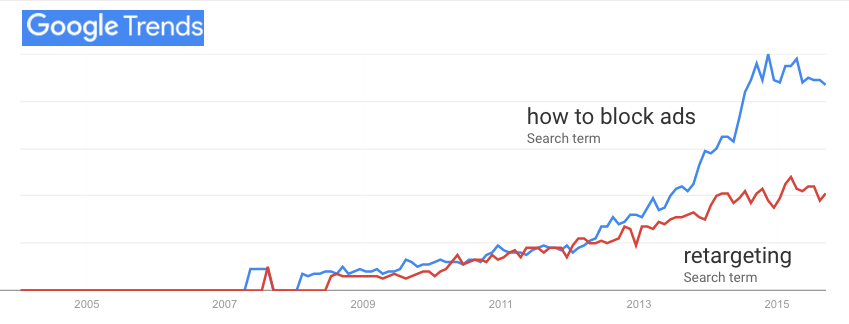
The IAB is blind to the simple fact that people hate being spied on and do what they can to stop it—mainly by turning off ads. By 2015, ad blocking was already the biggest boycott in human history. That boycott rose in direct response to obvious tracking, especially with retargeting. (That’s how one ad or advertiser keeps following you from site to site and app to app.) And the boycott is much bigger now:
- By Q2 2023, there were 912M active ad-blocking users worldwide, up 11% from Q4 2021. (Source: e/yeo, with more here)
- 1.77 billion people worldwide were blocking ads by Q2 of 2026. (Source: Backlinko, citing DataReportal and e/yeo).
- Privacy-focused browsers (like Brave, Safari, and Firefox) automatically block advertising elements and behavioural tracking scripts by default. This is in clear response to market demand.
The IAB earned all of that. Yet they still see ad blocking and tracking protection as problems to solve rather than clear and constructive signals from the marketplace.
So it should be clear by now that the old brownfield of consent has become a toxic wasteland of surveillance, lost privacy, and minimised human agency—led by an industry that has been hostile to privacy from the start.
In fact, consent is required for what Shoshana Zuboff calls Surveillance Capitalism. That form of capitalism is based on inferred or extracted consent. The only way we can defeat that regime is by re-basing e-commerce on contractual agreements in which customers take the lead. After all, it’s their privacy that needs protection.
The surveillance economy is limited entirely by its methods, which are built around grabbing attention, harvesting data, and guessing at people.
We can replace it with an intention economy that’s based on what customers actually want. The range of those wants far exceeds what companies and their systems can guess at. Far more business, and business improvement, opens up when market intelligence can flow both ways. In the consent/surveillance regime, it can’t, because all relationships are silo’d in sellers’ separate systems, all built to minimize customer interactions, by design. But relationships built on respectful contractual agreements can be far more capacious when those relationships start with forms of mutual trust that whole markets share. That’s what MyTerms makes possible.
Here is a quick outline of some additional benefits.
For customers, the most obvious one is getting rid of cookie notices, which are annoying and not worth the pixels they are printed on. If a company really does care about personal privacy, it’ll respect personal privacy requirements. This is how things work in the natural world, where tracking people like marked animals has been morally wrong for millennia. In the digital world, however, agreements need to be explicit, so programming and services can be based on them. MyTerms does that.
For business, MyTerms has lots of advantages:
- Reduced or eliminated compliance risk
- Competitive differentiation
- Lower customer churn
- A basis for real rather than coerced relationships
- A basis for better signalling in both directions
- Reduced or eliminated guesswork about what customers want, how they use products and services, and how both might be improved
Lawyers get a new market for services on both the buy and sell sides of the marketplace. Companies in the CMP (consent management platform) business (e.g. Admiral and OneTrust) have something new and better to sell to enterprises (and perhaps to people as well).
Lawmakers and Regulators can start looking at the Internet and the Web as places where freedom of contract prevails, and contracts of adhesion (such as what you “agree” to with cookie notices) are obsolete.
Developers can have a field day (or decade). Look for these categories to emerge
- Agreement Management Platforms — an evolutionary step forward from consent management platforms.
- Customer Relationship Management (CRM) – Make its middle name finally mean something.
- Customer Data Return (CDR) – Give, sell back, or share with customers the data you’ve been gathering without their permission since forever. Talking here to car companies, TV makers, app makers, and every other technology product with spyware onboard for reporting personal activity to parties unknown.
- Vendor Relationship Management (VRM) Tools and services — a customer hand for CRM to shake.
- Platform Relief – Free customers from the walled gardens of Apple, Microsoft, Amazon, and every other maker of hardware and software that currently bears the full burden of providing personal privacy to customers and users. Those companies can also embrace and help implement MyTerms for both sides of the marketplace.
- Personal AI (pAI)– Till and plant a vast new greenfield for countless companies, old and new. This includes Apple (which can make Apple Intelligence truly “AI for the rest of us” rather than Siri in AI drag), Mozilla (with its Business Accelerator for personal AI) , Kwaai (for open source personal AI), and everyone else who wants to jump on the train.
- Big meshes of agents, such as what these developers are all working on.
In the marketplace, we can start to see all these things:
- VRM + CRM will flourish, as described by Iain Henderson (one of MyTerms’ authors) in Towards Network-Based Ecosystems.
- We should expect improvements to digital public infrastructure, as relationships move out of Big Tech’s silos and into distributed relationship frameworks based on the Internet’s base peer-to-peer protocols.
- Predictions I made in The Intention Economy: When Customers Take Charge (Harvard Business Review Press, 2012) and Tim Berners-Lee made in the Attention vs. Intention chapter of This Is for Everyone: The Unfinished Story of the World Wide Web (Farrar, Straus and Giroux, 2025) will finally come true.
- There will be new dances between customers and companies. (“The Dance” is a closing chapter of The Intention Economy.)
- New commercial ecosystems can grow around a richer flow of useful information in both directions, based on shared interest and trust between customers and companies.
- Surveillance capitalism will be obsolesced — and replaced by an economy aligned with personal agency and mutual respect from contractual partners.
And much more.
So it would be helpful for the European Commission to expand its scope from protecting data subjects to empowering first parties. They can do that by welcoming MyTerms in the Omnibus Directive, expanding human agency into a new greenfield where boundless positive outcomes can flourish.
Drafts of myterms agreements are currently posted at MyTerms.info, which is a project of Customer Commons and MyData Global. You can also read more about MyTerms in writings by Iain Henderson, Nitin Badjatia, and me.
We also invite you to join the ProjectVRM list, where we can converse and collaborate on moving MyTerms forward.