

We’ve had cookie laws since the ’00s, the GDPR since the ’10s, and the CCPA since 2020. None of them has worked.
All those regulations are aimed at reducing the power of organizations to violate personal privacy. None is to empower people. That’s why, under those regulations, all we can do is agree to the terms organizations provide. We have no independent agency. All we have is what they promise, and their promises aren’t worth the pixels they’re printed on.
The only way we will get privacy is with contracts, which are laws that two parties make for themselves.
And the only way to make contracts work, at scale, is if we are the ones proffering those terms as first parties, and organizations agree to them as second parties. This flips the script on business-as-usual online.
By the old script, privacy is a grace of corporate obedience to selections in cookie notices, many of which provide no choice at all. There is “Accept,” and that’s it. In that case, all you’re accepting is a corporate privacy policy, which is typically just a fig leaf over the company’s hard-on for personal data.
Regardless of what you do with a cookie notice, chances are the company still tracks you like a marked animal. See here and here. You also have no easy of auditing compliance, because you keep no record of your “choices.” And we have that system because the incentives are worse than misaligned: they are completely broken.
See, if you are a typical website, you get paid for allowing third parties to harvest visitors’ personal data and use it to aim personalized advertising at their eyeballs. This is morally wrong on its face, but easily rationalized because it pays.
In the natural world, a store would never plant tracking beacons on every shopper, or require those shoppers to “choose” privacy protections by stripping naked and then selecting the purposes to which their personal tracking beacons will be put. Shoppers would avoid that store like the plague,
However, on the Net and the Web, we haven’t yet invented privacy, just as we hadn’t in the natural world before we invented clothing and shelter. So, on the Net and the Web, we are still naked as fish. As a result, a plague of near-ubiquitous surveillance has been raging online for decades. It is nearly impossible to avoid getting infected.
Most of that surveillance is for the $742 Billion surveillance-fed fecosystem* called adtech. And the only way we can obsolesce it is with a business ecosystem that works for everyone: customers and companies alike, and together.
We can do that now, with MyTerms.
MyTerms is the nickname for IEEE P7012 Standard for Machine Readable Personal Privacy Terms, which will be published next week after eight years in the works. (I chair the working group.)
It describes a protocol in the diplomatic sense: a way to reach and record agreements. Here is a diagram that shows how it works:
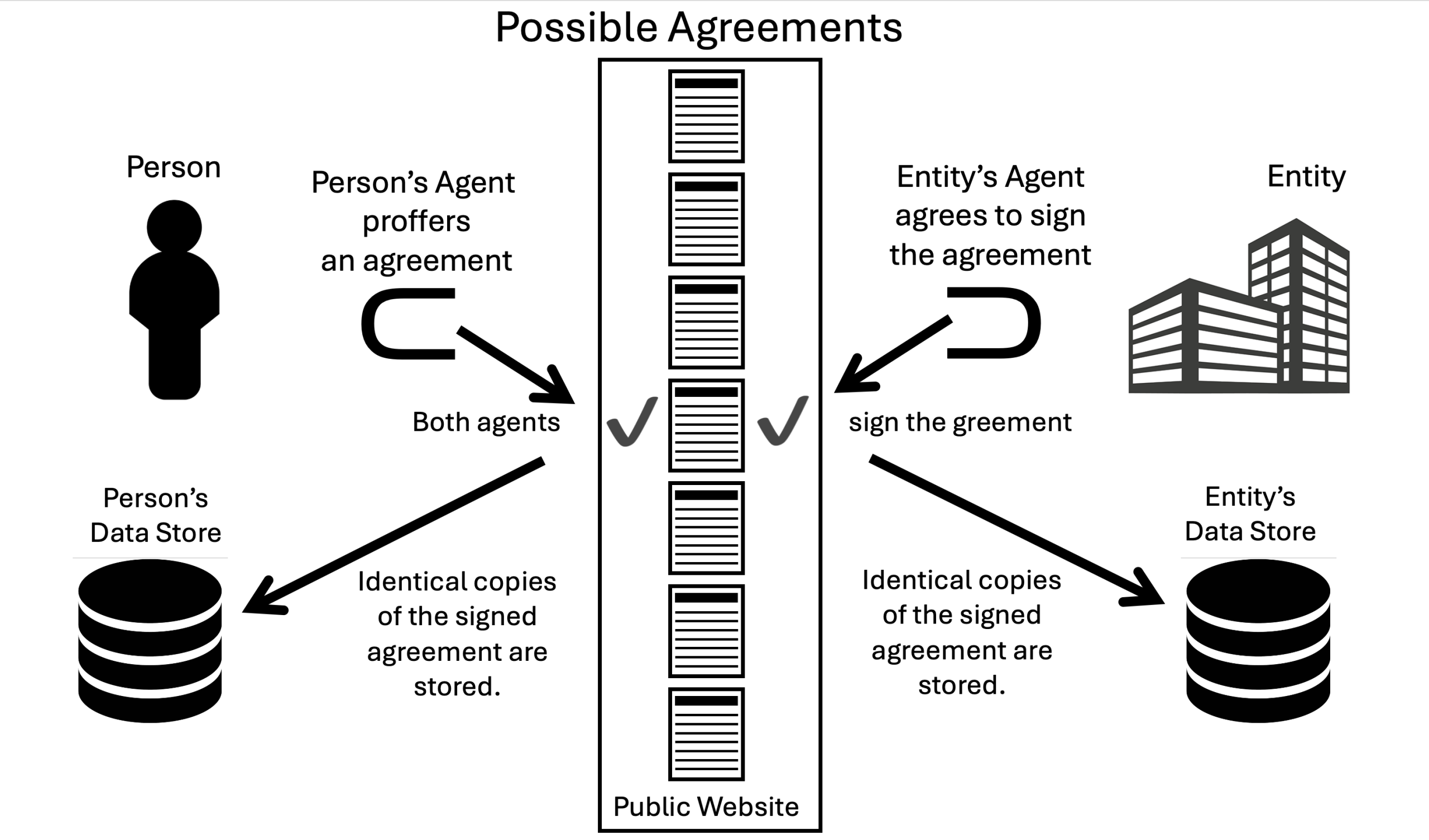
It is also the ultimate product of ProjectVRM, which began in 2006 with a mission: to prove that free customers are more valuable than captive ones—to companies, to markets, and to themselves. It was to ProjectVRM’s nonprofit spinoff, Customer Commons, that the IEEE came in 2017 with the challenge to create the MyTerms standard.
Of course, every agreement needs to be good for both sides. Right now we have five draft agreements for that. SD-BASE says “Service Delivery only.” This one requires that the site or service provide the visitor only what the visitor came for, and not to share personal data with third parties. This will make the site or service more inviting. (Customer Commons also plans to offer a trustmark to sites and services that sign MyTerms Agreements.) Lots of other mutually respectful agreements can also be built on top of SD-BASE: agreements that respect personal agency as well as privacy.
Other initial MyTerms agreements cover data portability, intentcasting, data-for-good, and AI training.
MyTerms will foster businesses and business methods that the surveillance fecosystem prevents. We describe how that will work, and some of the businesses MyTerms will create and improve, in The Cluetrain Will Run from Customers to Companies.
Of course, we need to develop tools and services for making that cluetrain run. Please tell us what you’ve got or plan.
The place to list those is in a new section of our Developments page. We also need to re-write and condense our privacy manifesto, and welcome help with both.
We also need to thank our many teams over the past two decades for jobs well done, even if many of those jobs didn’t go anywhere, mostly because they were too early.
Now is the time, because the world is fed up with surveillance—and it is easier than ever to develop tools and services using AI.
MyTerms will be announced on 28 January at this event in the Imperial Business School and online. Please come.
*The word fecosystem is apropos, kinda like Cory Doctorow’s ensittification. Spread both words.
