
Forrester Research has gifted marketing with a hot buzzphrase: zero-party data, which they define as “data that a customer intentionally and proactively shares with a brand, which can include preference center data, purchase intentions, personal context, and how the individual wants the brand to recognize her.”
Salesforce, the CRM giant (that’s now famously buying Slack), is ambitious about the topic, and how it can “fuel your personalized marketing efforts.” The second person you is Salesforce’s corporate customer.
It’s important to unpack what Salesforce says about that fuel, because Salesforce is a tech giant that fully matters. So here’s text from that last link. I’ll respond to it in chunks. (Note that zero, first and third party data is about you, no matter who it’s from.)
What is zero-party data?
Before we define zero-party data, let’s back up a little and look at some of the other types of data that drive personalized experiences.
First-party data: In the context of personalization, we’re often talking about first-party behavioral data, which encompasses an individual’s site-wide, app-wide, and on-page behaviors. This also includes the person’s clicks and in-depth behavior (such as hovering, scrolling, and active time spent), session context, and how that person engages with personalized experiences. With first-party data, you glean valuable indicators into an individual’s interests and intent. Transactional data, such as purchases and downloads, is considered first-party data, too.
Third-party data: Obtained or purchased from sites and sources that aren’t your own, third-party data used in personalization typically includes demographic information, firmographic data, buying signals (e.g., in the market for a new home or new software), and additional information from CRM, POS, and call center systems.
Zero-party data, a term coined by Forrester Research, is also referred to as explicit data.
They then go on to quote Forrester’s definition, substituting “[them]” for “her.”
The first party in that definition the site harvesting “behavioral” data about the individual. (It doesn’t square with the legal profession’s understanding of the term, so if you know that one, try not to be confused.)
It continues,
why-is-zero-party-data-important
Forrester’s Fatemeh Khatibloo, VP principal analyst, notes in a video interview with Wayin (now Cheetah Digital) that zero-party data “is gold. … When a customer trusts a brand enough to provide this really meaningful data, it means that the brand doesn’t have to go off and infer what the customer wants or what [their] intentions are.”
Sure. But what if the customer has her own way to be a precious commodity to a brand—one she can use at scale with all the brands she deals with? I’ll unpack that question shortly.
There’s the privacy factor to keep in mind too, another reason why zero-party data – in enabling and encouraging individuals to willingly provide information and validate their intent – is becoming a more important part of the personalization data mix.
Two things here.
First, again, individuals need their own ways to protect their privacy and project their intentions about it.
Second, having as many ways for brands to “enable and encourage” disclosure of private information as there are brands to provide them is hugely inefficient and annoying. But that is what Salesforce is selling here.
As industry regulations such as GDPR and the CCPA put a heightened focus on safeguarding consumer privacy, and as more browsers move to phase out third-party cookies and allow users to easily opt out of being tracked, marketers are placing a greater premium and reliance on data that their audiences knowingly and voluntarily give them.
Not if the way they “knowingly and voluntarily” agree to be tracked is by clicking “AGREE” on website home page popovers. Those only give those sites ways to adhere to the letter of the GDPR and the CCPA while also violating those laws’ spirit.
Experts also agree that zero-party data is more definitive and trustworthy than other forms of data since it’s coming straight from the source. And while that’s not to say all people self-report accurately (web forms often show a large number of visitors are accountants, by profession, which is the first field in the drop-down menu), zero-party data is still considered a very timely and reliable basis for personalization.
Self-reporting will be a lot more accurate if people have real relationships with brands, rather (again) than ones that are “enabled and encouraged” in each brand’s own separate way.
Here is a framework by which that can be done. Phil Windley provides some cool detail for operationalizing the whole thing here, here, here and here.
Even if the countless separate ways are provided by one company (e.g. Salesforce), every brand will use those ways differently, giving each brand scale across many customers, but giving those customers no scale across many companies. If we want that kind of scale, dig into the links in the paragraph above.
With great data comes great responsibility.
You’re not getting something for nothing with zero-party data. When customers and prospects give and entrust you with their data, you need to provide value right away in return. This could take the form of: “We’d love you to take this quick survey, so we can serve you with the right products and offers.”
But don’t let the data fall into the void. If you don’t listen and respond, it can be detrimental to your cause. It’s important to honor the implied promise to follow up. As a basic example, if you ask a site visitor: “Which color do you prefer – red or blue?” and they choose red, you don’t want to then say, “Ok, here’s a blue website.” Today, two weeks from now, and until they tell or show you differently, the website’s color scheme should be red for that person.
While this example is simplistic, the concept can be applied to personalizing content, product recommendations, and other aspects of digital experiences to map to individuals’ stated preferences.
This, and what follows in that Salesforce post, is a pitch for brands to play nice and use surveys and stuff like that to coax private information out of customers. It’s nice as far as it can go, but it gives no agency to customers—you and me—beyond what we can do inside each company’s CRM silo.
So here are some questions that might be helpful:
- What if the customer shows up as somebody who already likes red and is ready to say so to trusted brands? Or, better yet, if the customer arrives with a verifiable claim that she is already a customer, or that she has good credit, or that she is ready to buy something?
- What if she has her own way of expressing loyalty, and that way is far more genuine, interesting and valuable to the brand than the company’s current loyalty system, which is full of gimmicks, forms of coercion, and operational overhead?
- What if the customer carries her own privacy policy and terms of engagement (ones that actually protect the privacy of both the customer and the brand, if the brand agrees to them)?
All those scenarios yield highly valuable zero-party data. Better yet, they yield real relationships with values far above zero.
Those questions suggest just a few of the places we can go if we zero-base customer relationships outside standing CRM systems: out in the open market where customers want to be free, independent, and able to deal with many brands with tools and services of their own, through their own CRM-friendly VRM—Vendor Relationship Management—tools.
VRM reaching out to CRM implies (and will create) a much larger middle market space than the closed and private markets isolated inside every brand’s separate CRM system.
We’re working toward that. See here.








 The
The 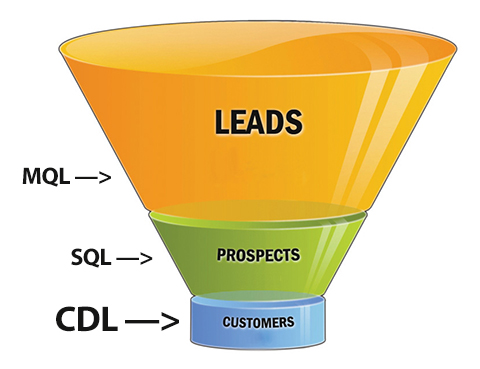 Imagine customers diving, on their own, straight down to the bottom of the sales funnel.
Imagine customers diving, on their own, straight down to the bottom of the sales funnel.