The Intention Economy subtitle. It’s the whole thing, right there.
A recent post by Simon Taylor on X expresses something important about AI agents and markets: if an AI agent arrives in a market with a clear mandate—
Get me X. Budget Y. Constraints Z.
—it obsolesces business-as-usual for digital marketing.
See, all of martech and adtech starts with the assumption that human intent is fuzzy and manipulable—and that the best customers are captive and manipulated. Let’s look at this from three angles, which are also the three things that happen in markets:
- transactions
- conversations
- relationships.
On the transaction side, companies invest heavily in tracking people, analyzing their behavior, targeting ads at them, and then (in many cases) rationalizing extremely wasteful results. Plus, of course, discounting or ignoring boundless negative externalities, such as the annoying people to new extremes and massively abusing personal privacy. (In fact, the system treats absent personal privacy as a base feature.) Anyway, the entire surveillance-based advertising fecosystem exists to guess what people want, or to influence what they might want.
On the relationship side, all we have so far is on the sell side: CRM, for Customer Relationship Management, and CX, for Customer Experience. We’ve been trying here to build (or to encourage building) systems for VRM, for Vendor Relationship Management, to give CRM customer hands to shake. But, in VRM’s absence, CRM is all we’ve got. One hand clapping. Or slapping. Or pushing prospects into a funnel.
What many of us, including Simon Taylor, suggest is facilitating conversation through AI agents. Simon’s case, specifically, is that an agent representing a person doesn’t need to be guessed at. It already knows the user’s intent. So there is no attention to capture and no desire to manufacture or manipulate. The demand signal is clear from the start. That’s why he says agents can collapse the attention economy.
The underlying shift in this direction has been visible for a long time. In The Intention Economy: When Customers Take Charge (Harvard Business Review Press, 2012), I argued that markets work best when customers drive them with clear signals of demand, rather than when sellers try to infer demand through surveillance and unwelcome persuasion. I also said markets can be far richer and more vital when customers and companies operate as equals, with relationships based on mutual interest rather than forms of coercion (such as “loyalty” programs that aren’t).
The work of Vendor Relationship Management (VRM) has been about correcting that imbalance.
Instead of companies managing relationships with customers through CRM (Customer Relationship Management) systems, we need customers able to manage relationships with vendors through VRM (Vendor Relationship Management) tools.
Note that relationship is the middle name of both CRM and VRM. Markets are not just about transactions. They are about relationships that continue over time.
That’s why a working intention economy will involve far more than simple buying transactions.
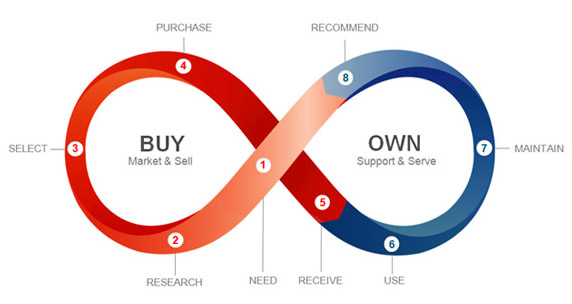
As Esteban Kolsky once put it, companies often focus almost entirely on the “buy cycle.” But customers live mostly in the “own cycle”—the long period of using, maintaining, fixing, improving, and learning from the products and services they already have:

In an intention economy, intelligence about that experience flows both ways between customers and companies. I wrote about this recently here:
Market intelligence that flows both ways.
VRM has long described one key mechanism for this: intentcasting, where customers signal their needs directly to the market rather than being targeted by guesses and ads.
Agents may make this far more feasible than it was when we first started talking about VRM nearly two decades ago.
But there’s an important point that often gets missed in current AI discussions.
The agency that matters most is the person’s, not the agent’s.
A personal AI agent is an instrument—like a phone, a computer, or a car. It acts on behalf of the individual, but the intention behind it must be the person’s own.
And that leads to another requirement:
The only truly personal agents will be owned and operated by individuals.
We don’t have that yet.
What we have instead are assistants that live inside corporate systems—helpful, sometimes impressive, but ultimately operating within feudal structures run by very large companies.
They are, at best, friendly suction cups on the tentacles of giants.
Individuals may well rent or borrow AI models from those giants. But the agents that represent us should operate inside our own environments, in our exclusive interest, rather than inside corporate systems whose interests may diverge from ours.
In other words, our agents should live in our own castles, not inside someone else’s kingdom.
When that happens—when individuals can show up in markets through tools they control—then the deeper shift becomes possible: from guesswork based on surveillance of captive customers to servicing self-qualified leads from free customers in the open marketplace.
Markets then begin to work the way markets are supposed to work: with demand and supply meeting in the open, in relationships that can last far beyond a single transaction.
This is also where work like MyTerms and the emerging ecosystem around personal AI becomes important. If individuals are to operate in markets through their own agents, those agents need ways to assert the person’s terms, preferences, and boundaries in forms that other systems can recognize and respect.
That is the direction VRM has been pointing for nearly twenty years: toward a world where individuals can arrive in markets with their own tools, their own data, and their own terms—and where markets can finally listen.
When that happens, markets will stop guessing what customers want—and start hearing them.
[Later… I actually wrote this post about a month ago, and put off publishing it while I worked on other things. Meanwhile, Adrian Gropper posted A Fork in the Road, which is required reading. I thank him for reminding me in the comments below, and for being a founding participant in ProjectVRM—going back to our earliest meetings almost 20 years ago.]





 and original CEO of
and original CEO of